REST vs GraphQL: Key Differences and Performance
Most teams do not choose REST or GraphQL based on careful architectural reasoning. They choose what they already know, or what sounds modern, and adjust later when something starts to fail.
The problem is that by the time the pain shows up, whether that is overfetching on mobile, caching complexity in GraphQL, or excessive round trips in REST, the architecture is already in place.
Let’s look at how each approach actually works, where the real differences are, and what should guide the decision for your specific system.
What Is REST?
REST (Representational State Transfer) is an architectural style for distributed systems, not a protocol. Roy Fielding defined it in his 2000 doctoral dissertation as a set of constraints that, when applied to HTTP-based APIs, produce systems that are scalable, stateless, and interoperable.
What makes an API RESTful is how well it adheres to those constraints, not a specification.
Core Principles of REST Architecture
To be considered truly RESTful, a system must follow a set of core principles that ensure consistent behavior and interoperability across the web.
- Statelessness: Each request must contain all information needed to process it. The server holds no session state between requests.
- Resource-based URLs: Data is exposed as resources with unique URLs. /users/42 refers to a specific user; /users/42/posts refers to that user's posts.
- Uniform interface: Clients interact using standard HTTP methods - GET to retrieve, POST to create, PUT/PATCH to update, DELETE to remove.
- Cacheability: Responses define themselves as cacheable or not. When properly marked, HTTP infrastructure (CDNs, proxies, browsers) can cache them automatically.
- Layered system: Clients do not need to know whether they are talking directly to the server or through an intermediary like a load balancer or API gateway.
How REST APIs Work in Real Systems
A REST API for a blog platform might expose:
GET /users/42 → returns user profile
GET /users/42/posts → returns user's posts
GET /posts/18/comments → returns comments on a post
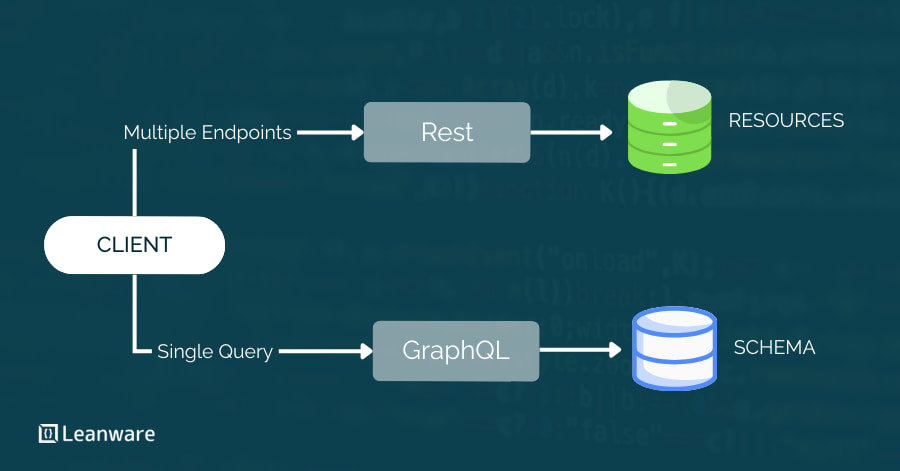
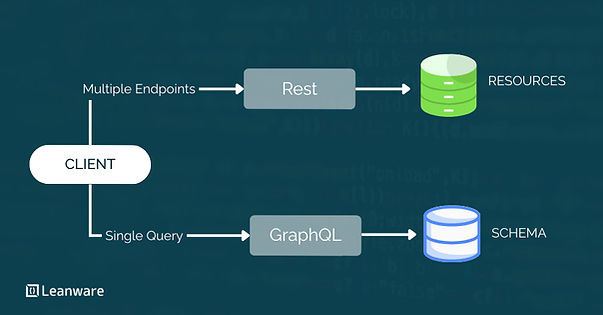
Each endpoint returns a fixed response shape defined by the server. If a client needs a user's profile, their recent posts, and the comment count on each, it makes three separate requests and assembles the data on the client side.
Strengths of REST
REST's main strength is its alignment with how HTTP works. GET requests are cacheable at the CDN or browser level with no extra configuration. Tooling is mature: Postman, OpenAPI/Swagger, curl, and most API gateways handle REST natively. Public APIs from Stripe and GitHub use REST because it is easy for third-party developers to consume without learning a query language.
For microservices, REST maps cleanly to service boundaries, and each service owns its endpoints with standard HTTP semantics.
Limitations of REST
The two main pain points are overfetching and underfetching. Overfetching happens when an endpoint returns more fields than the client needs. A mobile screen showing only a user's name and avatar still receives the full user object with every field the server includes.
Underfetching happens when one endpoint does not return enough related data, so the client makes additional requests - each round trip adding latency, especially on mobile connections. In systems with complex data relationships and multiple client types, this mismatch creates real performance and maintenance overhead.
What Is GraphQL?
GraphQL is a query language for APIs and a server-side runtime for executing those queries. Meta developed it in 2012 to handle mobile application data requirements and open-sourced it in 2015. GraphQL is transport-agnostic - it typically runs over HTTP, but the protocol is not part of the specification.
How GraphQL Queries Work
GraphQL APIs are defined by a schema in Schema Definition Language (SDL). Every type and field is described in the schema, and every field is backed by a resolver function that fetches the data. A query looks like this:
query {
user(id: "42") {
name
email
posts(limit: 5) {
title
commentCount
}
}
}
The server returns exactly those fields. If the client later needs the user's avatar, it adds avatar to the query - no endpoint change, no new API version.
The Single Endpoint Model
GraphQL uses one endpoint, typically /graphql, for all operations. Queries read data, mutations write it, and subscriptions handle real-time updates. The routing that REST distributes across multiple URLs is replaced by query structure.
This shifts responsibility from the server to the client: the server defines what is available through the schema; the client decides what to retrieve.
Strengths of GraphQL
Client-driven data fetching solves both overfetching and underfetching in a single request. A mobile client requests a minimal payload; a desktop client requests richer data - both use the same API without separate endpoints. GraphQL's strong typing creates a contract between client and server, and tools like GraphQL Code Generator can produce typed API clients from the schema automatically.
For products with multiple frontends consuming the same API, one GraphQL schema serves them all without version sprawl.
Limitations of GraphQL
The N+1 problem is the most common performance issue. When a resolver fetches a list of posts and calls a separate resolver for each post's author, that produces one query for the list plus one per post. Explicit batching through DataLoader is required to prevent this. Caching is harder - all GraphQL requests go to a single endpoint via POST, bypassing standard HTTP caching. Client-side caching through Apollo or persisted queries can address this, but both add tooling overhead.
Query complexity attacks are a real risk: without depth limiting and cost analysis, a deeply nested query can generate exponential database load. Authorization must also be handled at the field level, not just the endpoint level, which adds implementation complexity.
REST vs GraphQL: Key Differences
Both approaches transfer data over HTTP, but they differ in how data is structured, requested, and cached.
Data Fetching Model
In REST, the server controls the response shape. You call /users/42 and receive whatever that resource contains. In GraphQL, the client specifies which fields to return in the query itself. The server's schema defines what is available; the client decides what to retrieve. This distinction matters most in multi-client environments.
If a web app and mobile app both need user data in different shapes, REST typically requires separate endpoints or a generic response that includes everything. GraphQL serves both with the same endpoint and different queries.
Performance Considerations
GraphQL reduces network requests by consolidating related data into a single query - helpful on mobile networks where connection overhead is significant. However, it increases server-side processing: the server must parse the query, validate it against the schema, and run multiple resolvers. REST performs better for simple, frequently cached operations.
A GET /products response can be served from a CDN edge without hitting your backend. The equivalent GraphQL POST bypasses that infrastructure by default. Neither is universally faster - it depends on the use case and implementation quality.
Caching Strategies
REST leverages HTTP natively. Cache-Control and ETag headers let CDNs and browsers cache responses with no additional tooling. Each resource has a unique URL that acts as a stable cache key.
GraphQL requires a different approach. Client libraries like Apollo Client use normalized caching, storing each object by its ID. Persisted queries - where a hash replaces the full query string - can enable HTTP caching for GraphQL by converting POST requests to GET requests with stable identifiers.
Error Handling
REST uses HTTP status codes to communicate results: 400 for bad requests, 401 for authentication failures, 404 for missing resources, 500 for server errors. GraphQL always returns a 200 status, even when errors occur.
Errors appear as structured objects in the response body alongside any partial data, enabling partial success responses. This makes error detection less intuitive for tooling that relies on HTTP status codes.
Versioning
REST handles breaking changes through URL versioning: /v1/users becomes /v2/users when the response shape changes. GraphQL evolves the schema directly. New fields are added without breaking existing queries.
Old fields are marked deprecated in the schema, giving clients time to update. This works well when you control the clients, but requires schema discipline to avoid accumulating technical debt over time.
Overfetching and Underfetching: Why It Matters
These two problems represent the core architectural friction of REST APIs when client data needs diverge from server resource design. On constrained networks, the consequences are visible.
Example Scenario in REST
Suppose you are building a dashboard that shows a user's name, their five most recent post titles, and the comment count on each post. In REST:
GET /users/42
→ { id, name, email, address, preferences, avatar, createdAt, ... }
GET /users/42/posts?limit=5
→ [{ id, title, body, authorId, tags, publishedAt, ... }, ...]
GET /posts/1/comments/count
GET /posts/2/comments/count
...
You make at minimum three requests. The first returns far more user data than you need. The post responses include full body content you are not displaying. Each comment count requires a separate call. On a slow mobile connection, those round trips compound.
Equivalent Scenario in GraphQL
query {
user(id: "42") {
name
posts(limit: 5) {
title
commentCount
}
}
}
One request. The response contains exactly the fields requested. No extra data, no additional round trips. The payload is smaller and the latency is limited to a single network call.
The downside is that the server must implement commentCount as a resolvable field, and if that field queries the database per post, you hit the N+1 problem without proper batching in place.
Security Considerations
Authentication and transport security apply to both REST and GraphQL similarly. The architectural risks differ.
REST Security Patterns
REST's security model is well-established. OAuth 2.0 and JWT handle authentication and authorization. Rate limiting operates at the endpoint or IP level. API gateways apply throttling, logging, and WAF rules at the routing layer.
Because each endpoint has a predictable URL and HTTP method, access control policies are straightforward to define and audit.
GraphQL Security Risks
GraphQL requires explicit security controls that REST handles implicitly. Without query depth limiting, a client can construct arbitrarily nested queries that create exponential load on resolvers and the database. Cost analysis assigns a complexity score to each query and rejects those that exceed a threshold. Both controls must be implemented in your GraphQL server - they do not exist by default.
Schema introspection, which lets clients query the full API schema, is useful in development but should be disabled in production for non-public APIs. An exposed schema gives attackers a complete map of your data model. Authorization must also be applied at the field level in GraphQL, not just the endpoint level, because a single query can touch multiple types and resolvers.
Performance and Scalability
Scalability involves more than just raw speed. It is about how the system handles growth in users and data complexity over time.
Network Efficiency
GraphQL wins on network efficiency for complex, related data. Fewer round trips mean lower latency for operations that would require multiple REST calls. This is most pronounced in mobile applications and complex dashboard UIs where bandwidth matters.
REST wins on high-volume cacheable read traffic. When responses are served from a CDN without touching the backend, REST scales with lower infrastructure cost.
Backend Complexity
REST controllers are straightforward: one handler per endpoint, a known response shape, and clear database queries. Scaling a REST API means adding instances behind a load balancer. GraphQL resolvers add complexity.
Each field resolves independently, so a single query triggers multiple resolver functions. Managing batching through DataLoader, monitoring resolver performance, and controlling query cost require more engineering attention than REST endpoint maintenance.
When to Use REST
REST works best when your problem fits its constraints.
Best use cases for REST:
- Public APIs: Third-party developers expect REST. It requires no query language knowledge and works with any HTTP client.
- Simple CRUD systems: When your data model maps cleanly to resources and operations are straightforward reads and writes, REST is the simpler choice.
- Microservices: Inter-service communication over REST follows clear HTTP semantics. Each service owns its API surface and contracts are easy to define.
- Caching-heavy systems: Content APIs, product catalogs, and public data feeds benefit from native HTTP caching that REST enables without extra tooling.
- Legacy systems: REST is universally understood. Adding GraphQL to an existing REST-based system adds complexity without necessarily improving outcomes.
When to Use GraphQL
GraphQL works well when your data requirements and client diversity justify the added engineering effort.
- Complex dashboards: Analytics or admin interfaces that aggregate data from multiple entities in variable combinations fit the client-driven query model naturally.
- SaaS products with multiple clients: When a web app, mobile app, and third-party integration all consume the same API but need different data shapes, GraphQL serves all of them from one schema.
- Mobile applications: Precise payloads reduce bandwidth usage and improve performance on constrained connections.
- Rapidly evolving frontends: When the frontend team iterates quickly and adjusts data requirements frequently, GraphQL removes the dependency on backend API changes for each iteration.
Can REST and GraphQL Coexist?
Yes, and many production systems use both. A common architecture keeps internal microservices communicating over REST - well-defined contracts, easy caching, predictable load - while exposing a GraphQL gateway to frontend clients.
The gateway aggregates data from multiple REST services and presents a unified, queryable schema. This gives you REST's operational simplicity at the service layer and GraphQL's flexibility at the client-facing layer, without rewriting internal services.
Questions to Ask Before Deciding
Data complexity: Do clients need data from multiple resources in a single operation? If yes, GraphQL reduces round trips. If operations are mostly single-resource reads and writes, REST is simpler.
Client diversity: Do multiple clients with different data needs consume the same API? GraphQL handles this with one schema. REST handles it with separate endpoints or generic responses that include everything.
Caching requirements: Is the API primarily serving cacheable read traffic at scale? REST with HTTP caching is simpler and cheaper to operate. GraphQL requires additional caching infrastructure.
Team expertise: Does your team have experience designing GraphQL schemas and handling the N+1 problem? If not, budget time for that learning curve before committing to GraphQL in production.
API visibility: Is this a public API third-party developers will consume? REST is the conventional choice. GraphQL requires client developers to learn a query language and tooling.
Security requirements: Can your team implement and maintain query depth limiting, cost analysis, and field-level authorization? If not, GraphQL introduces security risks that REST does not.
Your Next Step
REST and GraphQL solve different problems, and neither is a single answer for every system. REST favors stability, simplicity, and strong infrastructure support. GraphQL favors flexibility and precise data delivery. The right choice depends on your team, your product, and how your system evolves.
You can also connect with us to review your current architecture, explore design options, and plan an API strategy that supports long-term growth.
Frequently Asked Questions
What is the main difference between REST and GraphQL?
REST exposes multiple endpoints where the server defines the response structure. GraphQL uses a single endpoint where the client specifies exactly what data it needs. REST is resource-based; GraphQL is query-based and client-driven.
Is GraphQL faster than REST?
Not inherently. GraphQL can reduce network requests by consolidating data into one query, which helps in complex UIs. However, it increases server-side processing. REST performs better for simple, cacheable operations where HTTP infrastructure handles the load.
When should I use GraphQL instead of REST?
Use GraphQL when building complex frontends, mobile apps, or SaaS dashboards that require flexible data fetching across multiple resources. It is well-suited for cases where minimizing overfetching and reducing multiple API round trips is a priority.
When is REST a better choice than GraphQL?
REST is better for simple CRUD systems, public APIs, microservices architectures, and projects that rely on HTTP-native caching. It is easier to implement and maintain for straightforward use cases.
Does GraphQL replace REST?
No. Many systems use REST internally and expose GraphQL as a gateway layer for frontend clients. Both can coexist depending on system architecture needs.
What is overfetching in REST?
Overfetching occurs when a REST endpoint returns more data than the client needs because the server controls the response structure. This increases payload size and reduces efficiency, particularly on mobile networks.
What is underfetching in REST?
Underfetching happens when a client must make multiple API requests to gather related data. Each extra round trip adds latency and network overhead.
Is GraphQL more secure than REST?
Neither is inherently more secure. GraphQL introduces specific risks - deep query attacks, resource exhaustion, and schema exposure - that require explicit mitigation. REST relies on endpoint-level access controls and standard rate limiting.
How does caching differ between REST and GraphQL?
REST leverages HTTP caching through Cache-Control and ETag headers, which work automatically with CDNs and browsers. GraphQL requires client-side caching strategies, such as normalized caching in Apollo Client, and persisted queries to enable HTTP caching.
Can REST and GraphQL be used together?
Yes. A common pattern uses REST for internal microservice communication and GraphQL as a unified API gateway for frontend applications. This approach combines REST's operational simplicity with GraphQL's client-side flexibility.