RAG Orchestration Services Guide | 2026 Guide
Building AI applications that answer questions accurately from your own data requires more than just an LLM. You need retrieval systems to find relevant information, ranking to prioritize results, and generation to produce coherent responses. RAG orchestration manages these components as a unified system.
According to Menlo Ventures, RAG adoption reached 51% among enterprises in 2024, up from 31% the previous year. Organizations use RAG for 30-60% of their AI use cases, particularly when accuracy, transparency, and grounding in proprietary data matter.
Let’s break down what RAG orchestration is, how it compares to search and grounding, and how teams implement it in real systems.
What Are RAG Orchestration Services?
RAG (Retrieval-Augmented Generation) combines information retrieval with generative AI. Instead of relying solely on an LLM's training data, RAG systems fetch relevant documents from your knowledge base and include them as context when generating responses.
Orchestration refers to coordinating multiple components in this pipeline: document retrieval, ranking, context assembly, prompt construction, generation, and post-processing. Each component can be swapped, tuned, or scaled independently.
A basic RAG system has three parts: a vector database for storage, a retriever for finding relevant chunks, and an LLM for generation. Production systems add re-rankers, query transformers, guardrails, caching layers, and evaluation components.
Why RAG Orchestration Matters for AI Workflows
LLM-based systems have grown more complex. Early implementations often involved a single API call to GPT-4 with some context stuffed into the prompt. Production systems now require:
- Multiple retrieval strategies (semantic search, keyword matching, hybrid approaches)
- Dynamic routing based on query type
- Re-ranking to improve relevance
- Citation tracking for explainability
- Fallback handling when retrieval fails
- Cost optimization across different model tiers
Orchestration frameworks manage this complexity. They provide abstractions for building pipelines, handle state between components, and enable observability into what's happening at each stage.
Without orchestration, teams end up with brittle, hard-to-debug systems where changes to one component break others. With proper orchestration, you can swap retrievers, test different chunking strategies, or upgrade LLMs without rewriting the entire application.
RAG vs Grounding vs Search
These terms often get conflated, and understanding the differences helps you choose the right approach for a given use case.
Understanding the Differences
Search is pure retrieval. Given a query, return relevant documents. Traditional search uses keyword matching (BM25). Modern search adds semantic similarity via embeddings. The output is a ranked list of results, not generated text.
Grounding anchors LLM responses in verified sources. When an LLM generates a response, grounding ensures claims are supported by retrieved evidence. This reduces hallucination by constraining the model to information present in the source documents.
RAG combines retrieval with generation. The system retrieves relevant documents, includes them as context in the prompt, and generates a synthesized response. RAG goes beyond returning search results by producing a coherent answer that draws from multiple sources.
Approach | Input | Output | Use Case |
Search | Query | Ranked documents | Finding specific documents |
Grounding | Query + LLM | Verified response | Ensuring factual accuracy |
RAG | Query | Generated answer with sources | Question answering over documents |
When to Use Each Approach
Use search when: Users need to find specific documents, not synthesized answers. Legal discovery, academic research, and document management systems often need search rather than generation.
Use grounding when: Accuracy is critical and hallucination risk is high. Legal AI tools, medical information systems, and compliance applications benefit from strict grounding where every claim must trace to a source.
Use RAG when: Users want answers, not document lists. Enterprise chatbots, knowledge assistants, and customer support systems typically need RAG to synthesize information across multiple sources into coherent responses.
Many production systems combine approaches. A customer support bot might use RAG for general questions, strict grounding for policy-related queries, and search when users explicitly request documentation.
How RAG Orchestration Works
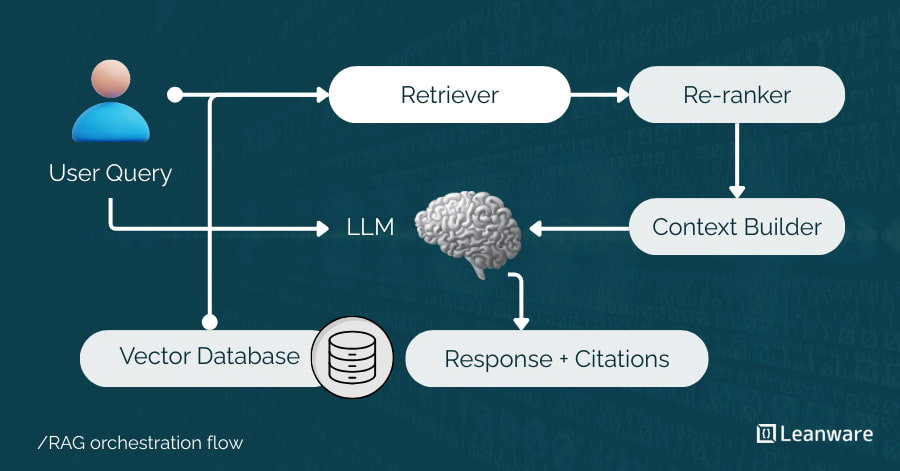
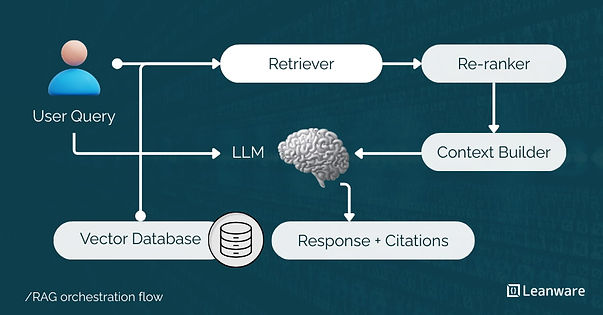
RAG orchestration coordinates the steps that turn a user query into a grounded response. It retrieves and ranks relevant data, builds a focused context, and passes it to a language model for generation, while controlling flow, fallbacks, and observability.
Architecture Overview
A typical RAG pipeline includes these components:
- Document processing: Ingests raw documents, splits them into chunks, generates embeddings, and stores them in a vector database.
- Query processing: Takes user input, optionally transforms it (query expansion, decomposition), and generates query embeddings.
- Retrieval: Searches the vector database for semantically similar chunks. May use hybrid approaches combining dense and sparse retrieval.
- Re-ranking: Applies a cross-encoder or other model to re-score retrieved chunks based on relevance to the specific query.
- Context assembly: Selects which chunks to include in the prompt, handles token limits, and formats the context appropriately.
- Generation: Sends the assembled prompt to an LLM and receives the response.
- Post-processing: Adds citations, applies guardrails, checks for hallucination, and formats the final output.
Key Components and Flow
The orchestration layer coordinates these components:
- User query arrives at the system.
- Query transformer may rewrite or expand the query for better retrieval.
- Retriever fetches candidate chunks from the vector database (typically 10-50 candidates).
- Re-ranker scores candidates and selects top results (typically 3-10 chunks).
- Context builder formats selected chunks with the original query into a prompt.
- LLM generates the response using the provided context.
- Post-processor adds source citations, applies output filters, and validates the response.
Orchestration frameworks like LangChain, LlamaIndex, and Haystack provide abstractions for building and managing these pipelines.
Benefits of Using RAG Orchestration Services
RAG orchestration helps AI give more accurate, context-aware answers and keeps systems modular and easier to scale. It also makes it simpler to monitor, test, and maintain components as workflows get more complex.
Improved Relevance and Context Awareness
RAG systems ground LLM responses in your actual data. This produces more accurate, relevant answers compared to relying on the model's training data alone.
Consider the difference:
Without RAG: "What is our refund policy?" → Generic response based on common refund policies the model learned during training.
With RAG: "What is our refund policy?" → Response citing your specific policy document, including exact timeframes, exceptions, and procedures.
Orchestration improves this further by enabling sophisticated retrieval strategies. Query decomposition breaks complex questions into sub-queries. Hybrid search combines semantic and keyword matching. Re-ranking ensures the most relevant chunks reach the LLM.
Scalable and Modular AI Systems
Well-orchestrated RAG systems offer engineering benefits:
Component isolation: Swap vector databases (Pinecone, Weaviate, Qdrant, pgvector) without changing retrieval logic. Upgrade LLMs without modifying the rest of the pipeline.
Testability: Test retrieval quality independently from generation quality. Evaluate re-rankers in isolation. A/B test different chunking strategies.
Observability: Track latency, token usage, and retrieval relevance at each stage. Identify bottlenecks and optimization opportunities.
Version control: Manage prompts, configurations, and pipeline definitions as code. Roll back changes when something breaks.
Cost optimization: Route simple queries to cheaper models. Cache frequent responses. Batch similar requests.
Common Industry Use Cases
RAG orchestration helps organizations turn complex, scattered data into clear, actionable answers - whether it’s for internal knowledge, customer support, or real-time decision-making.
Enterprise Knowledge Platforms
Large organizations use RAG to make internal knowledge accessible. Employees query documentation, policies, and historical decisions through natural language interfaces instead of navigating folder structures or keyword searches.
Companies like Glean and Notion AI use RAG architectures to let employees query internal documentation through natural language. These systems retrieve relevant documents and synthesize answers rather than forcing users to search manually.
According to K2View research, 86% of organizations augment their LLMs using RAG frameworks, recognizing that out-of-the-box models lack the customization needed for specific business needs.
Implementation typically involves:
- Ingesting content from wikis, SharePoint, Google Drive, and internal databases
- Chunking documents while preserving structure and metadata
- Building retrieval pipelines that respect access permissions
- Generating responses with citations back to source documents
AI-Driven Customer Support
Support teams use RAG to build chatbots that answer questions from knowledge bases, past tickets, and product documentation.
The system retrieves relevant help articles and previous ticket resolutions, then generates responses tailored to the specific question. This reduces response time and ensures consistency with existing documentation.
Open-source examples include LangChain-based support agents that connect to Zendesk, Intercom, or custom ticketing systems. These implementations demonstrate how to handle conversation context, escalation to human agents, and feedback collection.
Real-Time Decision Support Systems
Healthcare, financial services, and logistics use RAG for decisions that require auditable context.
Medical applications retrieve relevant clinical guidelines and research when physicians query about treatment options. The generated response includes citations, enabling verification of recommendations.
Financial services use RAG for research summarization, compliance checking, and client reporting. The audit trail from retrieval to generation matters in regulated environments.
Getting Started With RAG Orchestration
Choosing the right tools and frameworks for retrieval, indexing, and generation makes RAG orchestration manageable and aligned with your team’s workflow.
Tools, Platforms, and Frameworks
You can build RAG systems using frameworks that support flexible workflows, handle document-heavy retrieval, or provide clear, production-ready pipelines.
LangChain offers extensive integrations (100+ tools) and flexibility for building custom workflows. Best for complex, multi-step pipelines and agent-based architectures. Steeper learning curve but maximum control.
LlamaIndex specializes in data ingestion and indexing. LlamaHub provides connectors for 150+ data sources. Best for document-heavy applications where retrieval quality is the priority.
Haystack emphasizes production-ready pipelines with explicit, debuggable flows. Best for teams that need clear component boundaries and easy A/B testing of pipeline variations.
For vector storage, options include:
- Pinecone: Managed service, scales automatically
- Weaviate: Open-source with hybrid search
- Qdrant: Open-source with filtering capabilities
- pgvector: PostgreSQL extension, good for existing Postgres users
- Chroma: Lightweight, good for prototyping
Low-code options exist for teams without dedicated ML engineering. Azure AI Studio, OpenAI Assistants API, and platforms like Vectara provide managed RAG capabilities with minimal configuration.
Best Practices for Implementation
Start with data quality. Garbage in, garbage out. Clean your source documents, remove duplicates, and ensure metadata is accurate before building retrieval pipelines.
Choose chunking strategies carefully. Chunk size affects both retrieval quality and context utilization. Too small and you lose context. Too large and you waste tokens on irrelevant content. Test different strategies (fixed-size, recursive, semantic) on your actual queries.
Implement evaluation early. Use frameworks like RAGAS to measure retrieval relevance and answer quality. Without metrics, you're optimizing blindly.
Plan for latency. Production RAG involves multiple network calls (embedding, retrieval, generation). Cache embeddings, batch requests where possible, and consider async processing.
Build fallback strategies. What happens when retrieval returns nothing relevant? When the LLM refuses to answer? When the response seems hallucinated? Handle edge cases explicitly.
Monitor costs. LLM API calls add up. Track token usage per query, implement spending limits, and route appropriately based on query complexity.
Maintain observability. Log queries, retrieved chunks, and generated responses. You'll need this data to debug issues and improve the system over time.
Building Your RAG Strategy
RAG orchestration has become a standard pattern for enterprise AI applications. The 51% adoption rate reflects growing recognition that LLMs need grounding in organizational data to be useful.
Start simple. A basic RAG pipeline with a vector database, retriever, and LLM can demonstrate value quickly. Add complexity (re-rankers, query transformation, evaluation) as you understand your specific requirements.
The frameworks and tools have matured enough that implementation is straightforward. The harder work is data preparation, evaluation design, and ongoing optimization based on real usage patterns.
You can connect with us to design, implement, and optimize RAG workflows, making your AI applications more accurate, efficient, and scalable.
Frequently Asked Questions
What is RAG orchestration?
RAG orchestration coordinates the components of a retrieval-augmented generation system: retrievers, re-rankers, context builders, LLMs, and post-processors. It manages the flow from user query to final response, handling state, errors, and optimization across the pipeline.
What are the benefits of RAG orchestration?
Key benefits include improved accuracy through grounded responses, modularity that allows component upgrades without system rewrites, testability at each pipeline stage, and observability into system behavior. Orchestration also enables cost optimization by routing queries to appropriate model tiers.
Is RAG better than grounding or search?
It depends on the use case. RAG generates synthesized answers, which suits question-answering applications. Search returns document lists, better for discovery use cases. Grounding ensures factual accuracy, critical for high-stakes applications. Many systems combine approaches based on query type.
What tools are used for RAG orchestration?
Popular frameworks include LangChain (flexible, extensive integrations), LlamaIndex (data ingestion focus), and Haystack (production-ready pipelines). Vector databases like Pinecone, Weaviate, and Qdrant store embeddings. Managed platforms like Azure AI Studio and OpenAI Assistants provide low-code options.
Can I build a RAG system without coding?
Yes. Platforms like Azure AI Studio, OpenAI Assistants API, and Vectara offer managed RAG capabilities with configuration-based setup. These work well for standard use cases. Custom requirements typically need coding, but the barrier to entry has lowered significantly.
How can I find RAG orchestration developers or companies for enterprise AI solutions?
Companies looking to implement RAG orchestration typically work with specialized developers or consulting teams that can design and optimize AI workflows. Leanware is a top choice for building scalable RAG pipelines that integrate retrieval, ranking, and generation, helping enterprises create accurate, context-aware AI applications. Always evaluate a provider’s experience, past projects, and technical approach to ensure the solution aligns with your business requirements.