Custom RAG Development Services | Leanware

AI models are powerful reasoners, but they don't know your business. A large language model can write code, analyze data, and explain complex topics, but it can't tell you what's in your company's procurement policy, how your specific regulatory compliance process works, or what's documented in your internal knowledge base.
Retrieval-Augmented Generation (RAG) gives an AI system direct access to the knowledge that guides your work. It connects general-purpose LLMs to domain-specific information such as regulatory materials, technical specifications, operational procedures, and proprietary research.
RAG works far beyond basic question answering. It provides the foundation for any knowledge-heavy AI system, from customer support and compliance checks to documentation review and research analysis.
Let’s take a look at what RAG is, when it’s useful, how it works, and how teams apply it across different industries.
What Is RAG (Retrieval-Augmented Generation)?
RAG gives an AI system access to the information your organization relies on before it produces an answer. Instead of depending only on what the model learned during training, a RAG system searches your documents and data, retrieves the most relevant sections, and uses them to generate accurate, grounded responses.
RAG supports far more than basic Q&A. Teams use it to compare construction permit applications against building codes, process insurance claims based on policy language, review contracts for compliance issues, and generate technical documentation from engineering specifications. These tasks all require strong reasoning combined with direct access to specific and current information.
Definition: Retrieval + Augmentation + Generation
RAG works in three steps. First, retrieval uses semantic search to find relevant documents or sections from your knowledge base. The system converts both your query and stored documents into numerical representations (embeddings) that capture meaning, not just keywords. This lets it find relevant information even when exact words don't match.
Second, augmentation adds the retrieved content to the prompt with proper context. The system doesn't just dump raw text into the prompt. It formats the information, includes metadata like source documents and timestamps, and structures the context, so the LLM can use it effectively.
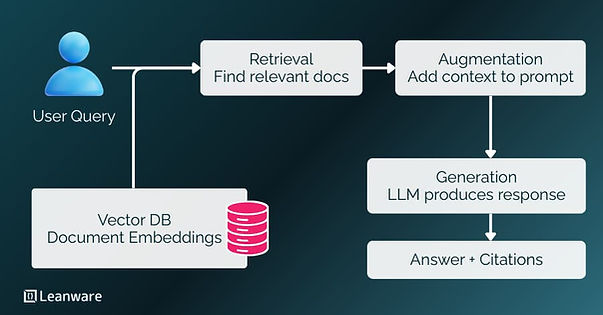
Third, generation produces a response grounded in the retrieved information. The LLM processes both your query and the retrieved context to generate an answer that references specific sources. This grounding reduces hallucinations and enables verification.
Consider analyzing a construction permit application against 15 different building codes. RAG retrieves relevant sections from each applicable code, provides them as context, and the LLM identifies specific compliance gaps with citations to the exact code sections. A plain LLM might produce plausible-sounding but incorrect analysis based on general construction knowledge.
Why Businesses Choose RAG Over Plain LLMs
Plain LLMs have fundamental limitations for business applications. They hallucinate plausible-sounding information, work from training data that becomes outdated, can't cite sources for verification, and lack company-specific knowledge. These problems create liability risks and reduce trust.
RAG sits between two alternatives. Prompt engineering alone is too limited. You can't fit your entire knowledge base into a prompt, and context windows have practical limits. Fine-tuning is expensive and slow. It requires significant compute resources, takes weeks to months, and you need to retrain every time information changes.
RAG provides the pragmatic middle ground. It costs less than fine-tuning, updates faster when information changes, handles large knowledge bases efficiently, and provides source citations for every answer. You can add new documents or update existing ones without retraining anything.
RAG Services & Solutions
RAG projects vary widely in scope and complexity. Some organizations need strategic guidance before building anything. Others have clear requirements and want full implementation. Some already have RAG systems that need optimization.
1. RAG Consulting & Strategy Planning
This phase evaluates whether RAG fits your requirements. It defines the use cases, checks data readiness, estimates ROI, and recommends a technical approach. Not every problem needs retrieval, so this step helps clarify when RAG is suitable.
Typical outputs:
- Architecture diagrams that show how retrieval, storage, and generation components interact.
- Implementation plans with milestones and timelines.
- Cost estimates for development, hosting, and ongoing updates.
Most discovery phases last one to two weeks and provide the information needed to decide how to proceed.
2. Custom RAG Model & Pipeline Development
This stage builds the retrieval and generation pipeline around your data. A custom setup avoids the assumptions that generic RAG frameworks often make about document structure or metadata.
Common tasks include:
- Designing chunking rules that keep context meaningful.
- Selecting embedding models suited to your domain.
- Setting up a vector store with indexing tuned for your retrieval patterns.
- Implementing filters, re-ranking, and hybrid search when needed.
- Creating prompt templates that organize retrieved content in a stable format.
A custom pipeline improves consistency and handles real-world data more reliably than out-of-the-box tools.
3. RAG System Integration & LLM Deployment
Once the pipeline works, it needs to integrate with existing infrastructure. This stage focuses on reliability, security, and maintainability.
Typical work involves:
- Connecting to internal APIs and data systems.
- Implementing authentication, authorization, and audit logs.
- Adding observability for retrieval steps and model outputs.
- Deploying in cloud, on-premise, or hybrid environments.
Integration often reveals constraints, such as limited API access, strict security requirements, or monitoring tools that do not track retrieval behavior. Addressing these issues ensures stable operation.
4. Data Preparation, Organization & Retrieval System Setup
Data preparation often takes more time than building the RAG system itself. Documents need parsing to extract text while preserving structure. Metadata needs tagging to enable filtering and attribution. Content needs semantic chunking that maintains coherent context. Duplicate or outdated content needs identification and handling. Updates need incremental processing without full reindexing.
Data sources vary widely. You might pull from PDFs, databases, APIs, Slack channels, Confluence wikis, SharePoint sites, or custom systems. Each source has different formats, update frequencies, and access patterns. The retrieval system needs to handle this diversity while providing consistent query interfaces.
5. Prompt Design, Fine-Tuning & Retrieval Augmentation
The interface between retrieval and generation determines system quality. Prompt templates structure how retrieved content appears to the LLM. Context window management balances providing enough information with staying under token limits. Citation formatting ensures responses reference sources clearly. Multi-step reasoning handles queries that need information from multiple documents.
Fine-tuning sometimes complements RAG. A fine-tuned model might better understand domain-specific terminology or follow specialized output formats. This combination works well when you need both domain adaptation and current information retrieval.
6. RAG System Evaluation, Optimization & Maintenance
A production RAG system needs ongoing evaluation because data, requirements, and models change over time.
Ongoing work includes:
- Testing retrieval strategies to compare accuracy.
- Monitoring answer quality.
- Updating embeddings.
- Managing data drift.
- Reducing latency and cost where possible.
Useful metrics:
- Retrieval precision: whether the system returned the right documents.
- Retrieval recall: whether it returned all relevant documents.
- Answer accuracy: whether the final output is correct.
- Citation quality: whether references are relevant and clear.
- Latency: how long each request takes.
Tracking these metrics keeps performance stable and helps guide improvements.
How RAG Supports Different Sectors
RAG applications vary by industry based on knowledge types, compliance requirements, and business processes.
1. Banking & Finance
Financial institutions use RAG for regulatory compliance Q&A that answers policy questions with citations to specific regulations, internal policy retrieval that helps employees find procedures quickly, financial document analysis that extracts insights from reports and filings, and fraud detection knowledge bases that provide investigators with relevant case histories and patterns.
2. Healthcare
Healthcare applications include clinical decision support systems that surface relevant medical literature and guidelines, patient record summarization that consolidates information from multiple systems, medical literature search that finds research papers matching specific criteria, and insurance claim processing that verifies procedures against coverage policies.
3. eCommerce & Retail
Retail uses RAG for product recommendations that check current inventory and specifications, customer service chatbots that answer questions using product documentation and order history, supplier contract analysis that finds terms and obligations, and trend analysis that synthesizes insights from multiple data sources.
4. Legal & Real Estate
Legal applications include case law research that finds relevant precedents with citations, contract review that identifies clauses and potential issues, due diligence automation that analyzes documents for acquisitions, and property comps analysis that pulls comparable sales data and market trends.
5. Manufacturing, Logistics & Supply Chain
Manufacturing uses RAG for equipment maintenance guides that help technicians find repair procedures, supply chain optimization that analyzes vendor performance and logistics data, quality control documentation that provides inspection criteria and standards, and vendor management systems that retrieve contract terms and communication history.
6. Education, Government & Public Sector
Public sector applications include student support systems that answer questions about programs and policies, grant and policy databases that help staff find relevant regulations and procedures, public records search that makes government documents accessible, and curriculum development tools that reference educational standards and materials.
7. Energy, Utilities, Insurance, Travel & More
Additional sectors use RAG for asset management in energy, claims processing in insurance, travel booking assistance, and technical documentation search across various industries. The pattern remains consistent: combining LLM reasoning with domain-specific knowledge retrieval.
Why Choose Leanware as Your RAG Development Company
RAG development requires both machine learning expertise and software engineering discipline. The ML side covers embeddings, vector databases, and prompt engineering. The engineering side handles data pipelines, API design, deployment architecture, and production operations.
Leanware brings these skills together with hands-on experience in building and integrating AI systems. The team has worked on RAG projects as part of broader AI and software development services, focusing on practical implementation rather than theoretical designs.
1. Proven Expertise and Real-World Projects
RAG systems fail for subtle reasons. Chunking strategies can miss context. Retrieval logic can return irrelevant documents. Prompt design can lead to hallucinations even when retrieval is accurate. These issues usually only become clear when a system is tested in real conditions.
Leanware has tackled these challenges in practice. This includes enterprise chatbots handling high query volumes, multi-language support, and systems integrated with existing data infrastructure. The emphasis is on stable, measurable performance rather than prototypes.
2. Enterprise-Grade Architecture & Data Security
Secure RAG systems require multiple layers:
- Encryption for data at rest and in transit.
- Access controls to limit what users can see.
- Audit logs to track usage and changes.
Some projects also require on-premise or air-gapped setups where data never leaves internal systems. Leanware designs architectures that meet these requirements while still supporting retrieval, embedding generation, and model inference.
3. Flexible, Modular Technology Stack
Not every project needs the same tools. Some work best with OpenAI models, others with Anthropic or open-source alternatives. Vector databases differ by scale and feature set. Modular design allows swapping components as needs change without rebuilding the whole system.
Leanware evaluates the stack based on project requirements, making it easier to maintain performance, control costs, and adjust over time.
4. Engagement Models for Any Organization
RAG projects can take many forms depending on scale and priorities:
- Short pilots to validate a concept.
- Fixed-scope implementations with clear deliverables.
- Staff augmentation to support internal teams and ongoing work.
Leanware adapts its approach to match organizational needs, providing guidance and execution together without overcomplicating the process.
RAG Development Process
A structured process reduces risk and ensures alignment between technical implementation and business needs.
1. Business Needs Assessment & Data Audit
Discovery workshops identify specific use cases and prioritize them by impact and feasibility. Data inventory catalogs available knowledge sources and assesses quality. Success metrics define what good performance looks like for your application.
This phase typically runs 1–2 weeks and delivers a project blueprint that guides development. Clear requirements upfront prevent expensive mid-project changes.
2. Data Alignment, Retrieval System Design & Prompt Engineering
Data preparation strategy defines how to process each source type. Embedding model selection balances capability, cost, and deployment constraints. Chunking approach determines how to split documents while preserving context. Retrieval architecture design specifies vector database configuration, filtering logic, and re-ranking mechanisms. Initial prompt templates structure how context appears to the LLM.
This phase runs 2–4 weeks depending on data complexity and retrieval requirements.
3. Building Retrieval + Augmentation Pipelines
Implementation includes vector database setup, data ingestion pipelines that process documents and generate embeddings, retrieval logic that finds relevant content, and re-ranking mechanisms that prioritize the most useful documents.
Development takes 3–6 weeks depending on data volume, source diversity, and retrieval complexity. Complex projects with multiple data sources and sophisticated filtering need more time.
4. LLM Integration & Deployment
Integration connects retrieval systems to LLMs through APIs. Response formatting structures output for your application. Citation handling ensures sources appear correctly. Deployment infrastructure runs in your chosen environment: cloud, on-premise, or hybrid.
This phase typically takes 2-3 weeks and results in a working system ready for testing.
5. Testing, QA & Performance Evaluation
Evaluation measures both retrieval quality and generation quality. Answer accuracy testing verifies responses match ground truth. Retrieval accuracy testing confirms the system finds relevant documents. Load testing ensures performance under expected traffic. Edge case identification finds failure modes.
Testing runs 2–3 weeks and produces performance benchmarks that inform optimization priorities.
6. Optimization, Monitoring & Ongoing Support
Performance tuning addresses issues found during testing. Monitoring dashboards track key metrics in production. Documentation enables your team to maintain and extend the system. Team training ensures staff can operate and troubleshoot effectively. Maintenance plans cover ongoing support and improvements.
This phase continues after launch as you gather production data and identify improvement opportunities.
Benefits of Using Custom RAG Services
RAG provides specific advantages over alternative approaches for certain use cases.
1. Improved Accuracy & Contextual Understanding
RAG systems cite sources, handle company-specific terminology, and stay current with real-time data. A plain LLM might confidently state outdated policy information or misunderstand internal jargon. RAG grounds responses in actual documentation.
2. Reduced Hallucinations and Reliable Source Attribution
Every answer includes citations to source documents. This reduces liability, increases trust, and enables verification. Users can check whether the system interpreted sources correctly. This matters critically for regulated industries where incorrect information creates compliance risks.
3. Faster, More Cost-Effective AI Solutions
Compared to fine-tuning, RAG deploys faster, updates easier, costs less for compute, and requires no retraining cycles. You can launch a RAG system in weeks rather than months. Adding new information means indexing new documents, not retraining models. Cost savings range from 60-80% compared to fine-tuning approaches for knowledge-intensive tasks.
4. Better Scalability and Flexibility Compared to Fine-Tuning Alone
RAG systems add new data sources without retraining, adjust retrieval behavior without model changes, update knowledge instantly, and handle multiple domains in one system. A fine-tuned model bakes knowledge into weights, making updates expensive and slow. RAG keeps knowledge separate, making changes straightforward.
Your Next Step
RAG isn't right for every project. If your knowledge base is small and static, prompt engineering might suffice. If you need style adaptation more than information retrieval, fine-tuning could be better. But if you're dealing with large, changing knowledge bases where accuracy and source attribution matter, RAG is worth exploring.
Start by clarifying your use case. What questions do you need answered? What documents contain the answers? Who will use the system and how often? These questions determine whether a pilot makes sense and what it should test.
A pilot project costs $15,000-$30,000 and runs 6–8 weeks. You get a working prototype with real data, performance benchmarks, and a clear picture of production requirements. This validates the approach before committing to full development.
You can reach out to our experts to evaluate RAG, clarify technical requirements, or plan a pilot project to improve information retrieval and decision-making.
Frequently Asked Questions
What does RAG actually do?
RAG connects an AI model to your company's documents and data so it can answer questions using current, accurate information rather than just what it learned during training. The system retrieves relevant content from your knowledge base and uses it to generate responses grounded in your actual documentation.
Is RAG becoming obsolete?
No. Some assume that longer context windows make RAG unnecessary, but RAG remains valuable for several reasons. It's more cost-efficient than stuffing millions of tokens into every request. Selective retrieval provides only relevant information rather than overwhelming the model. You can update knowledge by adding documents instead of regenerating massive contexts. RAG gives better control over sources and maintains privacy for sensitive data by retrieving only what's needed.
What are the different levels or types of RAG?
Naive RAG performs basic retrieval and generation. You retrieve documents, stuff them in a prompt, and generate a response. Advanced RAG adds re-ranking to prioritize the most relevant results, query rewriting to improve retrieval, and hybrid search combining semantic and keyword approaches. Modular RAG implements agentic workflows with multi-step reasoning, tool use for specialized tasks, and self-correction mechanisms. Use naive RAG for simple cases, advanced for production systems, and modular for complex reasoning tasks.
Can RAG systems replace or work alongside LLM-only solutions?
RAG complements rather than replaces LLMs. Use the LLM for reasoning and language generation. Use RAG for factual grounding and current information. Together they provide both capability: the LLM handles complex reasoning while RAG ensures factual accuracy through source documents.
How much does it cost to build a custom RAG system?
Pilot or MVP projects typically cost $15,000-$40,000 and validate the approach with a subset of data and a single use case. Mid-market production systems run $50,000-$150,000 for full implementation with multiple data sources and robust architecture. Enterprise implementations range from $150,000-$500,000+ depending on scale, integrations, and compliance requirements. Cost drivers include data complexity, scale requirements, number of integrations, and regulatory compliance needs.
How long does RAG development typically take from start to production?
Pilots take 6-10 weeks from kickoff to working prototype. Production systems need 3–6 months including all phases from discovery through launch. Enterprise implementations require 6–12 months due to additional security reviews, compliance requirements, and legacy system integrations. Clean, well-organized data accelerates timelines. Regulatory requirements and complex legacy integrations slow them down.
What can go wrong with RAG implementations, and how do you prevent it?
Poor chunking strategy creates wrong context sizes that miss important information or include irrelevant content. Inadequate retrieval misses relevant documents due to poor query formulation or embedding model limitations. Prompt engineering failures cause hallucinations despite good retrieval if the prompt doesn't properly instruct the model. Data quality issues surface when source documents contain errors or outdated information. Prevention requires thorough testing, evaluation frameworks, and iterative refinement based on real usage patterns.
Do I need RAG or would fine-tuning/prompt engineering be better for my use case?
Use RAG when you need current information that changes frequently, source attribution for verification, or access to large knowledge bases. Use fine-tuning for adapting style, format, or domain-specific reasoning patterns. Implement prompt engineering for simple tasks with stable requirements. Often the best solution combines approaches: fine-tune for domain adaptation, use RAG for information retrieval, and apply prompt engineering for output formatting.
What data do I need to provide and how much preparation is required?
Minimum requirements include access to knowledge sources like documents, databases, or wikis. Ideal scenarios provide structured metadata, clean formatting, and clear content ownership. Data preparation typically represents 40-50% of project effort. This includes parsing documents, extracting text, adding metadata, handling duplicates, and establishing update processes. These tasks are included in development services.
Which vector database should I use: Pinecone vs Weaviate vs Chroma vs Qdrant?
Pinecone offers managed service with easy setup, making it good for getting started quickly. Weaviate provides rich features and open-source flexibility, suitable for complex requirements. Chroma works well embedded in applications for lightweight use cases. Qdrant delivers fast performance and good scalability. Selection depends on scale, budget, deployment preference, and team expertise. Most projects can start with any option and migrate later if needs change.
How do you handle data security and compliance in RAG systems?
Security uses multiple layers: encryption for data at rest and in transit, access controls that enforce authorization policies, audit logging to track all queries and access, data residency options to keep information in specific regions, and on-premise deployment for highly sensitive data. Specific compliance approaches include SOC 2 infrastructure practices, HIPAA-compliant implementations for healthcare, and GDPR data handling practices for European information.
Can RAG integrate with our existing systems?
Yes. RAG systems pull data from existing platforms via APIs, database connections, or file exports. Common integrations include Salesforce, SAP, SharePoint, Confluence, Slack, and custom databases. You can choose between real-time sync for up-to-the-minute accuracy and batch processing for better performance with less frequent updates.
How much does it cost to maintain a RAG system after launch?
Typical ongoing costs include cloud infrastructure for vector databases and compute, API costs for embeddings and LLM calls, monitoring and observability tools, data updates and ingestion, and occasional optimization work. Small systems run $500-$5,000 monthly. Enterprise systems cost $5,000-$50,000 monthly depending on query volume, data size, and service level requirements. Retainer-based support options provide predictable costs for ongoing optimization and maintenance.
How do you measure if a RAG system is actually working well?
Key metrics include retrieval precision and recall (finding the right documents), answer accuracy (generating correct responses), citation quality (providing relevant sources), user satisfaction scores, and system latency. Measure these using evaluation datasets with known correct answers, human review of sample responses, and A/B testing of different approaches. Production monitoring tracks these metrics continuously to catch degradation early.
Can we start with a small RAG pilot before committing to full development?
Yes, and this approach is recommended. Typical pilots run 6–8 weeks, focus on a single use case, use a subset of your data, and cost $15,000-$30,000. Pilots deliver a working prototype, performance benchmarks against evaluation criteria, and a production roadmap. This de-risks the full investment by validating the approach with real data and use cases before scaling up.