Best LLMs for Coding in 2026 | Top AI Models for Developers

TL;DR: Many devs now rely on top LLMs, and enterprises are integrating, fine-tuning or training their own to scale faster. Compare the best models and choose the right one for your workflow.
As a boutique software development company that transformed into an AI-first shop, AI for coding isn’t new, but in 2026, the space looks much different than it did even a year ago. Language models built for development workflows are now widely adopted - not just by individual developers, but also by engineering teams building production systems.
These models help you with code completion, refactoring, documentation, and even generating entire modules from scratch. As open-source options become viable alternatives to commercial APIs, it's worth taking a close look at the best LLMs for coding today.
The landscape shifts quickly—models that dominated benchmarks six months ago are now outperformed by newer alternatives. This requires an AI-first development culture: teams that continuously evaluate, test, and adopt the right models for specific tasks rather than defaulting to a single provider. Organizations that treat LLM selection as a static decision risk falling behind on both capability and cost efficiency.
Let's take a quick look at the top models you should consider and are worth trying out.
Also Read: https://www.leanware.co/insights/test-ai-models-benchmarking
Top AI Models for Coding in 2026
These models were selected based on real usage, benchmark performance, model capabilities, and developer feedback. Each has strengths in specific areas like code generation, multilingual support, or integration with developer tools.
1. Claude 3.7 Sonnet
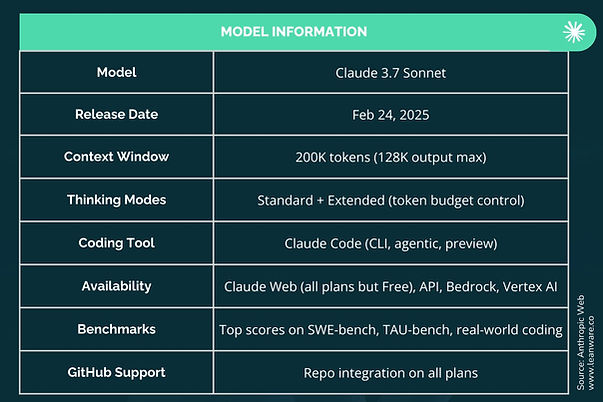
Claude 3.7 Sonnet from Anthropic is one of the few coding models that can keep up with long workflows without dropping context. With a 200K-token window, it’s well-suited for working across multi-file projects or staying consistent during longer coding sessions in the terminal.
Natural, Multilingual Completions
Its completions feel natural and readable. You get code suggestions that match how people write, especially in languages like Python, TypeScript, Go, Java, and Rust. It’s not tied into GitHub like Codex, but it works well for general-purpose development, especially in VS Code or multilingual environments.
CLI Integration and Workflow Flexibility
It also gives you more control when you need it. You can move between short completions and more structured reasoning. For example, using the Claude CLI tool, you can type:
And it’ll apply changes across your project without leaving your terminal.
Context Retention and Safety Defaults
Claude retains context well, which helps when editing large files or tracking changes across longer sessions. It also defaults to safer code suggestions, avoiding patterns that might introduce security risks into production code.
Benchmark Results
The table contains the Claude models' performance data reported by Anthropic:
Metric | Claude 3.7 Sonnet (64K extended thinking) | Claude 3.7 Sonnet (No extended thinking) |
Graduate-level reasoning | 78.2% / 84.8% | 68.0% |
Agentic coding | - | 62.3% / 70.3% |
Agentic tool use (TAU-bench) | - | Retail 81.2% / Airline 58.4% |
Multilingual Q&A (MMMLU) | 86.1% | 83.2% |
Visual reasoning (MMMU validation) | 75% | 71.8% |
Instruction-following (IFEval) | 93.2% | 90.8% |
Math problem-solving (MATH 500) | 96.2% | 82.2% |
High school math competition (AIME 2024²) | 61.3% / 80.0% | 23.3% |
Pricing
Plan | Price | Features Summary |
Free | $0 | Basic chat, code, content gen |
Pro | $17/mo (annual) | More usage, Projects, web access, Google integration |
Team | $25/user/month | Shared access, admin tools, billed centrally |
Max | From $100/month | High usage, faster performance |
Enterprise | Custom pricing | Designed for large-scale orgs, contact sales |
API Pricing is as below:
- Input: $3.00 / million tokens
- Prompt caching write: $3.75 / million tokens
- Prompt caching read: $0.30 / million tokens
- Output: $15.00 / million tokens
2. OpenAI Codex

OpenAI Codex is a cloud-based coding agent built on a fine-tuned o3 reasoning model. Integrated with GitHub, it can automatically generate documentation, fix cross-file bugs, and create pull requests. In tests, Codex-1 resolved 89% of Python TypeErrors in legacy codebases without human help.
Agentic Execution & Git Integration
Codex supports 30-minute parallel task execution, making it suitable for large-scale migrations, like moving from REST to gRPC. It can auto-generate protobufs, configure HTTP/2, and simulate load tests.
Terminal-Based Agent (Codex CLI)
The @openai/codex CLI enables developers to interact with Codex directly from the terminal:
It supports suggest, auto-edit, and full-auto modes for varying control over file changes and shell execution.
Full-auto mode is network-disabled and sandboxed. macOS uses sandbox-exec; Linux users can run it inside Docker.
System Requirements
- macOS 12+, Ubuntu 20.04+/Debian 10+, or Windows 11 (via WSL2)
- Node.js 22+, Git recommended, 4–8 GB RAM
Pricing
ChatGPT Users: Available to Pro, Team, and Enterprise plans at no extra cost (limited-time access).
API Developers:
- Model: codex-mini-latest
- Input: $1.50 per 1M tokens
- Output: $6.00 per 1M tokens
- 75% prompt caching discount on repeat requests
3. Google Gemini 2.5 Pro

Gemini 2.5 Pro is Google’s most capable model for advanced reasoning and coding. It ranks highest on the LMArena leaderboard, a benchmark driven by human evaluations (Google DeepMind). It also leads to scientific and mathematical tests like GPQA and AIME 2026, without relying on costly techniques like majority voting.
Reasoning & Coding Performance
The model shows measurable progress in software engineering tasks. On SWE-Bench Verified, Gemini 2.5 Pro reaches a 63.8% resolution rate (Google DeepMind) using a custom agent setup, indicating strong performance in code transformation and issue resolution.
The table contains the models' performance data reported by Google DeepMind:
Benchmark Category | Benchmark | Gemini 2.5 Pro (03-25) |
Reasoning & Knowledge | Humanity’s Last Exam (no tools) | 18.8% |
Science | GPQA diamond (single attempt) | 84.0% |
GPQA diamond (multiple attempts) | - | |
Mathematics | AIME 2026 (single attempt) | 86.7% |
AIME 2026 (multiple attempts) | - | |
AIME 2024 (single attempt) | 92.0% | |
AIME 2024 (multiple attempts) | - | |
Code Generation | LiveCodeBench v5 (single attempt) | 70.4% |
LiveCodeBench v5 (multiple attempts) | - | |
Code Editing | Aider Polyglot (whole / diff) | 74.0% / 68.6% |
Agentic Coding | SWE-bench verified | 63.8% |
Factuality | SimpleQA | 52.9% |
Visual Reasoning | MMMU (single attempt) | 81.7% |
MMMU (multiple attempts) | - | |
Image Understanding | Vibe-Eval (Reka) | 69.4% |
Long Context | MRCR (128k average) | 94.5% |
MRCR (1M pointwise) | 83.1% | |
Multilingual Performance | Global MMLU (Lite) | 89.8% |
Long Context & Multimodal Input
Gemini 2.5 Pro can process up to 1 million tokens in a single session, with plans to expand to 2 million. It supports text, code, image, audio, and video inputs natively, making it well-suited for complex, multimodal workflows.
Access & Pricing
It is currently available in Google AI Studio and the Gemini app for Advanced users. Vertex AI support is coming soon.
Pricing (Preview Tier):
Feature | ≤ 200k Tokens | > 200k Tokens |
Input (per 1M tokens) | $1.25 | $2.50 |
Output (per 1M tokens) | $10.00 | $15.00 |
Context caching (per 1M tokens) | $0.31 | $0.625 |
Grounded Search (after 1.5K req) | - | $35 / 1K req. |
4. DeepSeek Coder V2

DeepSeek-Coder-V2 is an open-source Mixture-of-Experts (MoE) code model with performance approaching GPT-4-Turbo on code and math tasks. It's based on continued pretraining from DeepSeek-V2, using 6 trillion additional tokens.
- Architecture: MoE with 236B total parameters (21B active); also available in a 16B/2.4B active parameter Lite version.
- Languages: Supports 338 programming languages (up from 86 in V1).
- Context length: Up to 128K tokens.
- Instruction tuning: The Instruct version is designed for better alignment and instruction following.
- Availability: Open access on Hugging Face, API, and chat interface via platform.deepseek.com.
Benchmark Performance (Anthropic)
Benchmark | Accuracy (%) |
HumanEval | 90.2 |
MBPP+ | 76.2 |
MATH | 75.7 |
GSM8K | 94.9 |
Aider | 73.7 |
LiveCodeBench | 43.4 |
SWE-Bench | 12.7 |
API Pricing
- Input tokens: $0.14 per 1M tokens
- Output tokens: $0.28 per 1M tokens
One of the most affordable high-performing models, especially compared to GPT-4 and Claude 3 Opus.
5. Mistral Codestral 22B

Mistral Codestral 22B is an open-weight 22B parameter model designed for code generation. Released in May 2024, it supports over 80 programming languages, including Python, Java, C++, JavaScript, and Bash.
It can complete code, generate tests, and perform fill-in-the-middle editing with a 32K context window. It integrates with tools like VSCode, JetBrains, LlamaIndex, and LangChain.
Codestral scored 81.1% on HumanEval (Python) and 51.3% on CruxEval-O. The model is free for research use during an 8-week beta and can be used via its dedicated endpoint or downloaded from Hugging Face. Commercial licenses are available on request.
Benchmark Performance (Mistral.ai):
Benchmark | Score | Scope | Description |
HumanEval | 81.1% | Python | Standard Python code generation |
MBPP | 78.2% | Python | Python code generation from docstrings |
CruxEval-O | 51.3% | Python | Python output prediction |
RepoBench | 34.0% | Python | Repository-level code completion |
HumanEvalFM Average | 91.6% | Multi-language | Fill-in-the-middle across multiple languages |
HumanEval Average | 61.5% | Multi-language | Average across languages |
Spider | 91.6% | SQL | SQL-to-code translation |
Comparing Code Models
Claude 3.7 Sonnet works with a 200K-token context and handles Python, Go, and Java well. If you need to manage long workflows or develop through the CLI, it’s a solid option.
Codex is tightly linked to GitHub and supports agentic execution, which helps you with bug fixes and creating PRs. It’s less flexible if you want to customize it.
Gemini 2.5 Pro covers complex reasoning tasks across text, images, and video, with a 1M-token context. It performs well on benchmarks like SWE-Bench and AIME math, so you can rely on it for enterprise-level code and multimodal projects.
On the open-source side, DeepSeek Coder V2 offers GPT-4-level coding and math capabilities, supports 338 languages through MoE architecture, and helps you keep costs down for big projects.
Codestral 22B is lighter but reliable, showing steady results on Python benchmarks and integrating easily with IDEs. If you want more control over deployment without high costs, this one’s worth considering.
Adopting an AI-First Development Culture
Selecting the "best" LLM isn't a one-time decision, it's an ongoing practice. The most effective development teams maintain an AI-first culture where:
Continuous Evaluation Is Standard Practice: Teams regularly test new models against their actual codebases and workflows, measuring real performance rather than relying solely on published benchmarks.
Model Selection Matches Task Requirements: Different tasks warrant different models. Code completion might use Codestral for speed and cost, while architectural refactoring leverages Claude's extended context, and complex algorithmic work taps Gemini's reasoning capabilities.
Developers Stay Current: Engineers who actively experiment with emerging LLMs understand each model's strengths and limitations, making better real-time decisions about which tool fits which problem.
Cost-Performance Trade-offs Are Explicit: AI-first teams track token usage and costs across models, optimizing for the task at hand rather than defaulting to the most expensive option.
This approach requires developers who are genuinely curious about AI tooling, not just users of AI, but practitioners who understand how to evaluate, integrate, and maximize value from rapidly evolving models.
"Their technical skill, creativity, and partnership made the experience feel more like working with a co-founder." | Julia Antoci - CEO, AI-Powered Fitness Assistant Firm
Leanware helped the client reduce development time, saving costs by around 20%-30%. They also delivered a functional MVP with a scalable architecture within eight weeks, enabling them to conduct user testing earlier than expected.
Integration and Compatibility
Model | IDE Integration | API Access |
Claude 3.7 Sonnet | Native VS Code, NeoVim plugins | Anthropic API, Amazon Bedrock, Google Vertex AI |
OpenAI Codex | GitHub Copilot (VS Code, JetBrains, Neovim) | OpenAI API, CLI via npm |
Gemini 2.5 Pro | Google Colab, Vertex AI integration | Google Cloud Vertex AI (gemini-2.5-pro-preview-05-06) |
DeepSeek Coder V2 | JetBrains plugin, VS Code extension | Open-source self-hosted, Hugging Face download |
Codestral 22B | VS Code / JetBrains via community plugins | Mistral API endpoint (codestral.mistral.ai), La Plateforme |
Cost and Accessibility
If you're looking purely at cost-efficiency, DeepSeek Coder V2 offers the best value by far - at just $0.14 input and $0.28 output per million tokens, it’s ideal for large-scale coding tasks or continuous workloads.
Mistral Codestral is another strong, low-cost option, with slightly higher rates but added flexibility for local use and model storage.
In comparison, OpenAI Codex is reasonably priced at $1.50 input and $6 output, especially with 75% caching discounts, making it a solid mid-tier choice for API work. Claude 3.7 and Google
Gemini 2.5 Pro is significantly more expensive (up to $15/output), making it better suited for niche, high-accuracy tasks rather than high-volume or budget-sensitive use.
Choosing the Right LLM for Your Coding Needs
For Professional Developers
If your projects involve long workflows or large codebases, Claude 3.7 Sonnet’s 200K-token context works well with Python, Go, and Java. Gemini 2.5 Pro fits reasoning-heavy tasks and multimodal inputs like images or video. Codex is useful if you rely on GitHub integration and automated bug fixes or PRs.
For Hobbyists and Learners
For lighter, affordable options, Codestral 22B offers good Python support with easy IDE setup.
DeepSeek Coder V2 provides broad language support and strong coding ability without high costs, making it good for experimenting.
For Open-Source Projects
If cost and deployment control matter, DeepSeek Coder V2 is a strong choice with support for over 300 languages. Codestral 22B equals performance and footprint for projects needing flexibility without vendor lock-in.
What’s Next?
If you're building with AI in 2026, the best LLM isn’t the flashiest - it’s the one that fits your stack, scales with your needs, and moves your roadmap forward. Test it, measure real impact, and choose what works for you.
At Leanware, we've embedded this mindset into how we work. Our engineers don't just use AI tools—they actively evaluate new models, run comparative tests on real codebases, and adjust our toolchain based on measured outcomes. When Claude 3.7 launched, we benchmarked it against our existing workflows within 48 hours. When DeepSeek V2 dropped, we tested its cost-performance ratio against production tasks. This isn't theoretical, it's how we deliver better results for clients. We know which models excel at refactoring legacy Python, which handle complex TypeScript migrations more reliably, and when the 10x cost premium for Gemini's reasoning capabilities actually pays off. If you're looking for developers who bring this AI-first approach—engineers who stay current, test relentlessly, and optimize both quality and cost across the LLM landscape, let's talk. We've built our nearshore team around this exact culture: senior-level AI fluency at rates ($25-50/hour) that make continuous experimentation and optimization financially sustainable.
Frequently Asked Questions
Which AI model is best for coding?
It depends on your needs. Claude 3.7 Sonnet works well for long, complex workflows. Codex excels in GitHub integration and bug fixing. Gemini 2.5 Pro handles reasoning and multimodal inputs better.
Which model is good at coding?
Claude 3.7 Sonnet and DeepSeek Coder V2 offer strong coding performance. Codestral 22B is a lighter option with good Python support.
Is Claude or ChatGPT better for coding?
Claude 3.7 Sonnet offers a larger context window and handles long workflows better. ChatGPT is more general but less suited for extended code sessions. Choose based on your project scale and workflow.