Agent Evaluation Frameworks: Methods, Metrics & Best Practices
As AI agents become increasingly integrated into business operations, evaluating their performance is essential for ensuring reliability, efficiency, and user satisfaction. They provide a structured approach to measure how well an agent performs tasks, responds to users, and adapts to changing contexts.
Moreover, by combining technical metrics like accuracy and latency with human-centered ones such as coherence and satisfaction, organizations can achieve a more balanced view of performance.
This article explores the key methods, essential metrics, and proven best practices that help organizations assess, refine, and scale AI agents for real-world impact
What Is an Agent Evaluation Framework?
An Agent Evaluation Framework is a structured system designed to systematically assess how well an AI agent performs across various dimensions such as task effectiveness, reliability, safety, and compliance. It goes beyond just measuring accuracy or correctness of responses, evaluating the agent’s behavior in real-world, dynamic, multi-turn interactions, including decision-making and tool usage workflows.
This framework involves designing representative tests, applying relevant automated and human-in-the-loop metrics, and continuously monitoring the agent’s performance throughout its lifecycle.
Why We Need Agent Evaluation Frameworks
Use Cases & Benefits
Real-World Applications:
- Conversational agents (customer service chatbots, virtual assistants)
- Robotics (industrial automation, service robots)
- Autonomous driving systems (self-driving cars)
- Virtual assistants (personal productivity and smart home AI)
Benefits
- Accountability: Enables tracing and explanation of AI decisions to stakeholders and regulators.
- Performance Optimization: Identifies weak spots, benchmarks improvements, and aligns agent outputs with desired KPIs.
- Safety Assurance: Detects and mitigates risks such as harmful outputs, biases, or ethical violations.
- Reliability: Ensures consistent behavior across varying conditions and over time.
- Trust Building: Provides transparency and consistent measurement, building user and business confidence in AI agents.
Key Challenges
- Reproducibility: Difficulties in consistently replicating evaluation outcomes due to stochastic AI behavior and environmental variability.
- Subjectivity: Evaluation of complex agent behaviors often involves subjective judgments, making standardization challenging.
- Simulating Real-World: Replicating diverse, dynamic real-world scenarios and edge cases at scale for thorough testing is complex.
- Lack of Standardized Benchmarks: There is no universally agreed-upon set of benchmarks or metrics for holistic evaluation of AI agents across all domains, complicating comparability and regulatory oversight.
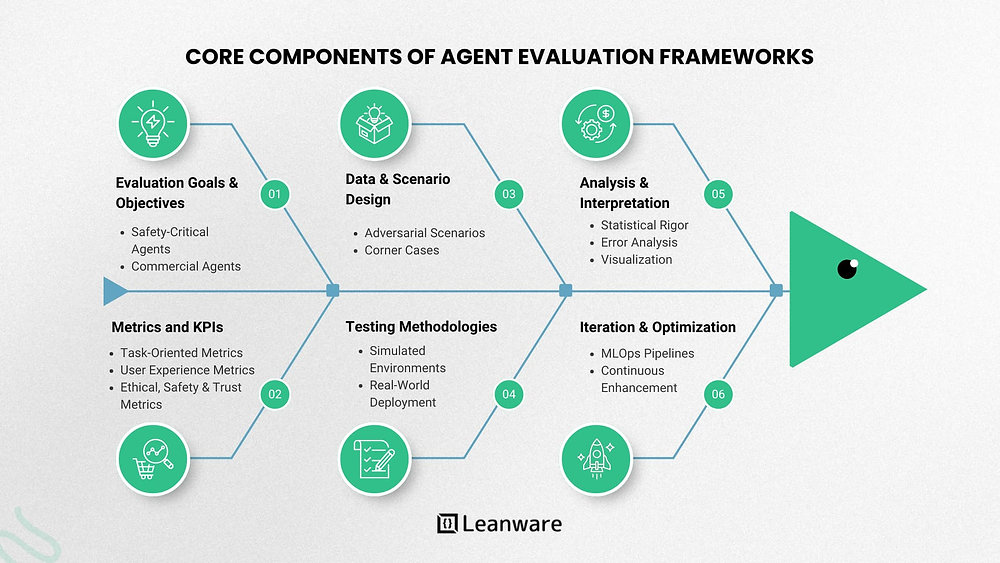
Core Components of Agent Evaluation Frameworks

Evaluation Goals & Objectives
Evaluations serve varied purposes such as validating an agent’s performance, identifying failure points, or comparing different models. The specific goals depend heavily on the agent’s domain — for instance, safety-critical agents like autonomous vehicles prioritize safety and failure containment, whereas commercial agents may focus more on user satisfaction and efficiency
Metrics & KPIs
Metrics vary by application and should reflect meaningful success criteria for the agent’s tasks and context:
Task-Oriented Metrics
- Accuracy of responses or decisions
- Task completion rate (e.g., successful route planning for drones)
- Latency or response time
- Resource efficiency, such as computational cost
User Experience Metrics
- User satisfaction and trust scores
- Engagement metrics
- UX-based A/B testing outcomes
Ethical, Safety & Trust Metrics
- Hallucination rate (frequency of incorrect/invented responses)
- Detection of harmful or biased outputs
- Fairness indicators across user groups
- Explainability or transparency scores
Data & Scenario Design
Evaluation demands representative test datasets capturing the diversity and complexity of realistic use cases. This includes adversarial scenarios that challenge agent robustness and corner cases that may provoke unexpected behaviors
Testing Methodologies
Simulated Environments
- Examples include AI gym environments, scenario modeling, and synthetic user simulations.
- These enable rapid, cost-effective iteration and controlled stress testing.
Real-World Deployment
While costly and complex, deploying agents in real settings is necessary for mission-critical applications like autonomous driving to validate true operational readiness.
Analysis & Interpretation
Results require statistical rigor, error analysis, and visualization for actionable insights. Tools like dashboards and custom analytic notebooks facilitate understanding performance trends and pinpointing failure modes.
Iteration & Optimization
Evaluation is an ongoing cycle: evaluation informs improvements, which are then re-evaluated. Many organizations implement MLOps-style pipelines to automate and scale this process for continuous agent enhancement.
Popular Agent Evaluation Frameworks & Tools
Several notable evaluation frameworks and tools have emerged to rigorously assess AI agents. These include open-source toolkits and proprietary systems tailored for diverse use cases, supporting everything from debugging workflows to enterprise-grade observability.
OpenAI’s Evaluation Framework
OpenAI offers a comprehensive evaluation framework featuring model evals with structured prompts designed to test a range of capabilities and performance thresholds. This framework emphasizes interpretability, allowing transparency into why models make specific decisions, which is valuable for debugging and compliance.
Benchmarking Suites
Popular benchmarking suites like HELM (Holistic Evaluation of Language Models) and LM Evaluation provide standardized environments and metrics to compare large language models and AI agents across tasks. While these suites are excellent for broad comparisons, they often lack domain-specific customization and may not fully capture real-world agent complexity.
Custom Evaluation Pipelines
Many organizations develop custom evaluation pipelines tailored to specific applications. For example, an autonomous vehicle company might build a pipeline combining simulation scenarios, real-world sensor data tests, and safety audits, while a customer service chatbot team might integrate live user feedback analysis with automated response correctness checks.
Best Practices & Guidelines
Ensuring Transparency & Explainability
Document all evaluation processes clearly, use interpretable scoring methods, and produce shareable reports so stakeholders can understand agent behavior and trust the evaluation results.
Bias & Fairness Considerations
Actively mitigate training data biases, perform evaluation across diverse demographic groups, and incorporate fairness-aware metrics to ensure equitable agent behavior.
Handling Edge Cases & Failures
Implement structured stress testing frameworks, utilize adversarial attack simulations, and design fail-safe evaluation criteria to uncover and prepare for rare but critical failure modes.
Governance & Auditability
Align evaluations with compliance standards such as the EU AI Act, maintain reproducible evaluation workflows, and enable internal audit trails to meet regulatory and organizational requirements.
Case Studies & Examples
Conversational Agents
Evaluations focus on dialogue coherence, user helpfulness, and minimizing toxic or biased language, similar to OpenAI’s practice with ChatGPT evaluations.
Autonomous Systems
Metrics include path accuracy, collision rates, and robustness of failover strategies as used in drone navigation systems.
Recommendation / Decision Agents
Assessment centers on user satisfaction, decision quality, and trust calibration, typical of recommender system validations.
Future Trends in Agent Evaluation Frameworks
Self-evaluation & Self-improvement
Agents will increasingly incorporate internal evaluation and retraining mechanisms based on analyzing failure logs, enabling autonomous self-improvement.
Continuous Live Monitoring
Post-deployment monitoring will become essential, leveraging observability tools and AgentOps platforms to track live performance and quickly detect regressions or anomalies.
Cross-agent Comparisons & Benchmarking Markets
Emerging platforms may offer standardized “agent ratings” akin to model marketplaces or trust indices, enabling transparent cross-agent performance comparisons and market-driven trust assessments.
You can consult with our team to evaluate your project needs and identify the most effective approach.
Final Words
A well-defined agent evaluation framework is critical for maintaining consistent performance, trust, and scalability in AI-driven systems. By aligning evaluation methods with real-world use cases and combining both technical and human-centered metrics, organizations can identify strengths, address weaknesses, and ensure continual learning.
The effective measurement not only improves agent reliability but also enhances user experience and business outcomes. As AI agents evolve, ongoing evaluation and iteration will remain key to unlocking their full potential in dynamic environments.