Harness Engineering for AI Agents: What It Is and How to Build It

AI agents can browse the web, write code, call APIs, query databases, and make decisions across multi-step workflows - all without a human in the loop. That's exactly what makes them hard to test.
A unit test can tell you whether a function returns the right value. It cannot tell you whether your agent will correctly decide to cancel a flight booking when the user says "actually, never mind." It cannot tell you whether your orchestration layer handles a tool timeout gracefully, or whether your agent recovers from a malformed API response mid-task.
Testing AI agents requires a different kind of infrastructure. That infrastructure is what harness engineering builds.
What Is Harness Engineering?
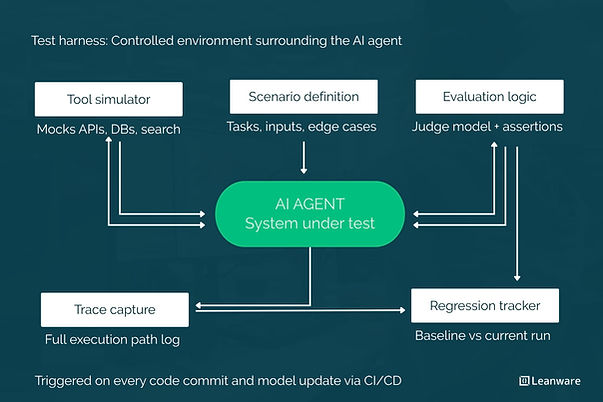
Harness engineering is the practice of building the controlled environments that surround a software component during testing. The harness supplies everything the component needs to run: simulated dependencies, predefined inputs, execution controls, and validation logic. The goal is a repeatable, isolated environment where you can observe exactly how the system behaves under specific conditions.
For traditional software, that means mocking a database or stubbing an API response. For AI agents, the problem is more complex. The "dependencies" include language models with probabilistic outputs, tool call sequences that vary between runs, long-horizon task execution with intermediate state, and external services that the agent decides to call based on its own reasoning.
Harness engineering for AI agents is the discipline of building infrastructure that can handle all of that and still produce reliable, actionable test results.
Why Standard Testing Doesn't Work for Agents
Most software behaves deterministically. Given the same input, you get the same output. You can write an assertion, run the test, and know whether it passed.
AI agents don't work that way.
The same prompt can produce different tool call sequences across runs. The agent might accomplish the correct end goal through a different sequence of steps each time. It might succeed on nine runs and fail on the tenth for reasons that have nothing to do with your code. And "failure" itself is harder to define - did the agent get the wrong answer, or did it get the right answer through a reasoning path that happens to be brittle?
These properties make standard testing frameworks insufficient. You need infrastructure that can:
- Run agents through realistic multi-step scenarios repeatedly
- Evaluate outcomes rather than just outputs
- Simulate the tools, APIs, and services the agent will call in production
- Capture the full trace of the agent's reasoning and tool use
- Flag regressions when a model update changes behavior, even if the final answer looks correct
That's a harness problem, not a test-writing problem.
The Core Components of an Agent Test Harness
Tool Simulators
In production, your agent calls real tools - a web search API, a code execution environment, a CRM, a database. In your harness, those tools are replaced with controlled simulators that return predictable responses.
This matters for two reasons. First, real tools introduce variability: search results change, APIs go down, databases drift. A simulator returns the same response every time, so a test failure means something in your agent changed - not something in the external world. Second, real tool calls cost money and have side effects. You don't want your test suite booking flights or sending emails.
Tool simulators should cover the full range of conditions your agent will encounter in production: successful responses, error responses, timeouts, malformed data, and edge cases specific to your domain.
Scenario Definitions
A scenario is the full context for one test case: the task description, the initial state, the sequence of tool responses the simulator will return, and the criteria for what a passing outcome looks like.
Scenarios should cover the happy path, but that's the easy part. The more important scenarios are the hard ones: ambiguous instructions, mid-task errors, tool call failures, contradictory information across sources, and tasks that require the agent to recognize it cannot complete the goal and say so.
For agent testing, scenario coverage is more important than line coverage. The question is not whether your code ran - it's whether your agent handled the situations it will actually encounter.
Evaluation Logic
This is where agent testing diverges most sharply from traditional testing. You cannot always write a deterministic assertion for an agent's output.
If the task is "summarize this document," the right summary is not a fixed string. If the task is "book the cheapest available flight," the right answer depends on what the simulator returned. If the task is "answer the user's question," a correct answer might come in many different forms.
Agent harnesses need evaluation logic that can handle this. Some evaluations are deterministic: did the agent call the right tool, did it pass the right parameters, did it write to the correct field. Others are model-based: a judge model reviews the agent's final output and rates it against a rubric. Others are behavioral: the agent should not have made more than three tool calls to answer a simple factual question.
The right mix depends on your agent's task. The point is that validation logic in an agent harness is not just assertions - it's a designed evaluation system.
Trace Capture
An agent's final output is only part of what matters. The reasoning path - which tools it called, in what order, with what inputs, and how it used the results - is equally important for understanding failures and regressions.
A good harness captures the full execution trace for every test run. When a test fails, you can see exactly where the agent went wrong: the wrong tool call, the misinterpreted response, the incorrect decision at a branch point. Without trace capture, debugging a failing agent test is guesswork.
Regression Tracking
Model updates break things. A new version of your underlying LLM might handle ambiguous instructions differently, call tools in a different order, or produce subtly different outputs that pass your existing evaluations but fail in ways you haven't tested yet.
Agent harnesses need to run on a schedule, not just on code commits, because the agent's behavior can change when the model changes - even if you haven't touched your code. Regression tracking means comparing current run results against a baseline so that model-driven behavior changes surface before they reach production.
How Harness Engineering Fits Into an Agent CI/CD Pipeline
A well-built agent harness integrates into your deployment pipeline the same way a traditional test suite does - with some additions.
On every code commit: Run the full scenario suite against your tool simulators. Catch failures in orchestration logic, prompt formatting, tool call handling, and output parsing before anything ships.
On every model update: Re-run your behavioral evaluations against the new model. Flag any scenarios where the pass rate dropped, where the agent's reasoning path changed significantly, or where edge case handling degraded.
On a regular schedule: Run a broader evaluation suite against a larger scenario set, including scenarios generated from recent production traces. This catches drift that gradual changes introduce over time.
Before major releases: Run end-to-end scenarios against real tools in a sandboxed environment. This is the closest you get to production conditions while still controlling for side effects.
What Makes Agent Harnesses Hard to Build
Probabilistic Outputs
You cannot assert that the agent's response will equal a fixed string. You need evaluation logic that can determine whether a variable output is correct, which requires either a rubric, a judge model, or a well-defined success criterion.
Getting this right takes iteration - early evaluations tend to be either too strict (flagging correct responses) or too lenient (passing incorrect ones).
Long Horizon Tasks
An agent that completes a ten-step task generates a lot of intermediate state. The harness needs to track that state, provide the right simulator responses at the right points in the sequence, and evaluate not just the final output but whether the agent took a reasonable path to get there.
Tool Call Sequences That Vary
Even when the agent reaches the correct conclusion, it might get there through different tool call sequences across runs. Your harness needs to distinguish between legitimate variation (different valid paths to the same correct answer) and problematic variation (unpredictable behavior that happens to produce the right answer sometimes).
Keeping Simulators Current
Your tool simulators need to reflect how the real tools actually behave, including their failure modes, rate limits, and schema changes. As your production tools evolve, your simulators drift out of sync unless you actively maintain them. Stale simulators are worse than no simulators - they give you confidence in test results that don't reflect reality.
Tools Used in Agent Harness Engineering
The agent evaluation ecosystem is newer and less standardized than traditional testing infrastructure, but several tools have emerged:
Evaluation frameworks: LangSmith, Braintrust, Weights & Biases Weave, and PromptFlow provide infrastructure for running agent evaluations, capturing traces, and tracking results over time.
Tool simulation: WireMock and similar HTTP mocking tools handle external API simulation. For more complex tool environments - code execution sandboxes, browser automation, database interactions - custom simulators built on top of existing mocking infrastructure are common.
Orchestration frameworks: If you're building on LangGraph, CrewAI, AutoGen, or similar frameworks, your harness needs to integrate with how those frameworks handle tool calls and agent state. Most of these have test utilities or community tooling for this.
Judge models: For outcome-based evaluation, a separate LLM call that rates the agent's output against a rubric. Claude, GPT-4, or a fine-tuned evaluator model can serve this role.
Building Your First Agent Harness
Start with your most important failure modes - not your happy path. The happy path is easy to test and unlikely to break. What are the scenarios where your agent failing would cause real problems? Start there.
Define concrete success criteria before you build the harness. "The agent completed the task correctly" is not a testable criterion. "The agent called the booking tool with the correct parameters and confirmed the action to the user" is.
Build your tool simulators to cover failure modes from the start. An agent that only gets tested against successful tool responses will fail in production the first time an API returns a 429.
Capture traces on every run. You will need them.
Run your harness on every code change and every model update. The two most common sources of agent regressions are changes to your prompts and changes to the underlying model. Both require automated detection.
The Cost of Not Building This
AI agents that reach production without a real test harness behind them behave unpredictably. They fail in ways that are hard to reproduce, hard to diagnose, and hard to explain to users. They degrade silently when model updates change their behavior. They handle edge cases inconsistently.
The investment in harness engineering is front-loaded. The cost of skipping it compounds over time.
For any team building agents that take real actions in the world - calling APIs, modifying data, interacting with users autonomously - a test harness is not optional infrastructure. It's what makes the difference between an agent you can trust and one you're constantly firefighting.
If you're building AI agents and need help designing the testing infrastructure behind them, Leanware can help - from harness design to full CI/CD integration.
Frequently Asked Questions
What is harness engineering for AI agents?
It's the practice of building controlled test environments specifically designed for AI agent systems - infrastructure that simulates the tools agents call, defines realistic scenarios, evaluates variable outputs, and captures execution traces for debugging and regression tracking.
Why can't I use standard unit tests for AI agents?
Standard unit tests assume deterministic behavior. AI agents produce variable outputs, follow different tool call sequences across runs, and can be affected by model updates that have nothing to do with your code. Agent testing requires evaluation logic and scenario infrastructure that standard testing frameworks don't provide.
What is a tool simulator in an agent harness?
A controlled substitute for the real tools your agent calls in production - APIs, databases, search engines, code execution environments. Simulators return predictable responses so that test failures reflect agent behavior, not external variability.
How do you evaluate an AI agent's output?
Through a combination of deterministic assertions (did the agent call the right tool with the right parameters), model-based evaluation (a judge model rates the output against a rubric), and behavioral checks (did the agent stay within expected reasoning patterns). The right mix depends on the task.
What is trace capture in agent testing?
Recording the full execution path of an agent run - every tool call, every input and output, every decision point. Traces are essential for debugging failing tests and understanding why an agent behaved differently than expected.
How often should I run my agent harness?
On every code commit, on every model update, and on a regular schedule to catch gradual drift. Agent behavior can change when the underlying model changes, even if your code stays the same.
What tools exist for agent harness engineering?
LangSmith, Braintrust, Weights & Biases Weave, and PromptFlow for evaluation infrastructure. WireMock and similar tools for HTTP simulation. Judge models (Claude, GPT-4, or fine-tuned evaluators) for outcome-based evaluation.