Chain of Thought Prompting Techniques: How It Works
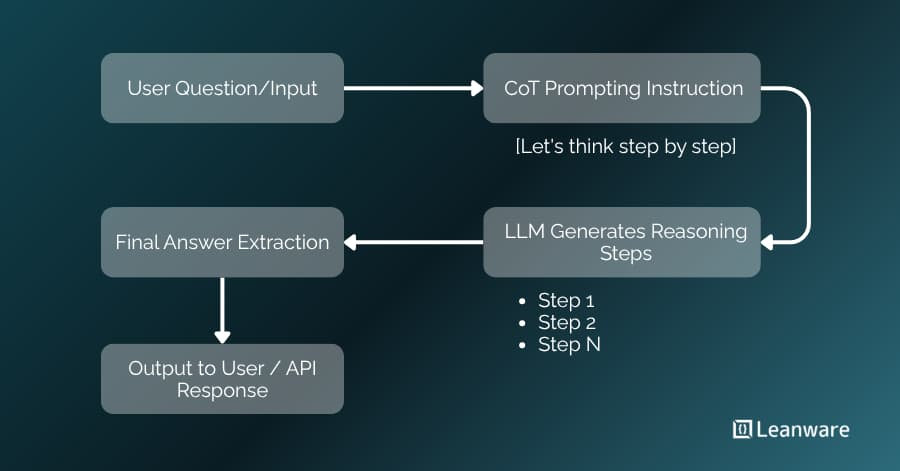
Chain of Thought (CoT) prompting guides language models to reason through problems step by step rather than producing an immediate answer.
By exposing intermediate reasoning, CoT has been shown to improve performance on tasks involving logic, mathematics, and multi-step inference.
In this article, we’ll cover the fundamentals of CoT, look at its key variants, and share best practices for putting it to work in real-world workflows.
What Is Chain of Thought Prompting?
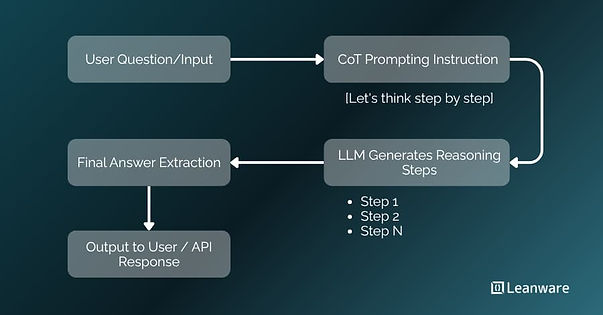
Chain of Thought prompting instructs language models to generate intermediate reasoning steps before producing a final answer.
Introduced by Wei et al. in 2022, this approach showed that providing few-shot examples with explicit reasoning improves performance on arithmetic, commonsense, and symbolic tasks.
Wei et al. introduced this approach in their 2022 paper "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," showing that few-shot examples with explicit reasoning significantly improve performance on arithmetic, commonsense, and symbolic reasoning tasks.
Why It Matters in Prompting
CoT addresses a fundamental limitation in standard prompting. When you ask a model to solve a complex problem directly, it attempts to generate the answer in one step. This works for simple queries but fails on problems requiring multiple logical steps.
Standard zero-shot prompt: "Calculate 47 × 23" CoT prompt: "Calculate 47 × 23. Let's work through this step by step."
The second prompt triggers the model to show its work, exposing the reasoning process and reducing calculation errors.
Why Chain of Thought Prompting Is Effective
CoT reflects human problem-solving: we break complex problems into smaller steps, reducing cognitive load and catching errors more easily. Language models benefit the same way.
Step-by-step reasoning creates checkpoints where the model can course-correct, building a coherent solution instead of jumping straight to the answer.
CoT is especially useful for:
- Multi-step arithmetic.
- Logical reasoning with multiple premises.
- Commonsense reasoning requiring background knowledge.
- Tasks where the solution path matters as much as the answer.
Comparisons to Other Prompting Methods
Zero-shot prompting asks the model to answer directly. Few-shot shows example Q&A pairs but skips reasoning. CoT combines few-shot with explicit reasoning chains:
- Zero-shot: "23 apples, 20 used, answer: 3"
- Few-shot: Multiple Q&A pairs without steps
- CoT: "23 apples, 20 used → 23 - 20 = 3 → Answer: 3 apples remain"
CoT outperforms zero-shot and standard few-shot prompts, with the advantage growing as problems get more complex.
How Chain of Thought Prompting Works
A well-structured CoT prompt contains three components:
- Task description: Clear problem statement
- Reasoning steps: Intermediate calculations or logical steps
- Final answer: Conclusion clearly marked
Example structure:
Question: A store had 37 books. They sold 18 and received 25 new books. How many books do they have now?
Let me work through this:
- Started with: 37 books
- After selling 18: 37 - 18 = 19 books
- After receiving 25: 19 + 25 = 44 books
Answer: 44 books
The formatting matters. Clearly separated steps help the model maintain structure. Explicit calculation markers ("37 - 18 = 19") work better than implied math.
Underlying Mechanisms in LLMs
Transformer models generate text token by token, using attention to reference earlier context. When producing reasoning steps, the model builds an internal representation of the problem at each step.
Each new step adds tokens to the context, which subsequent predictions can attend to, effectively using its own output as working memory.
CoT’s effectiveness grows with model scale: models under roughly 10B parameters show minimal benefit, while models above 100B parameters maintain coherent reasoning over longer sequences and demonstrate significant gains.
Variants and Extensions of Chain of Thought
- Zero-Shot CoT adds instructions like "Let's think step by step" to trigger reasoning without examples. Large models leverage training data to perform step-by-step reasoning. GPT-4, Claude, and similar models respond well to this approach.
- Automatic CoT (Auto-CoT) lets the model generate its own reasoning examples. Diversity-based sampling selects representative questions, produces reasoning chains, and uses them as few-shot examples, reducing manual prompt engineering.
- Multimodal CoT extends reasoning to image-text tasks. Models like GPT-4V and Gemini generate reasoning steps referencing both visual and textual data, performing interpretation, extraction, and calculations.
- Self-Consistency & Prompt Chaining improve reliability. Self-consistency generates multiple chains and selects the majority answer, reducing errors. Prompt chaining links multiple CoT prompts sequentially, letting outputs feed into subsequent reasoning steps for complex workflows.
Template for Chain of Thought Prompts
Math problems:
Q: [Problem statement]
Let's solve this step by step:
1. [Identify known values]
2. [Apply relevant operation]
3. [Show calculation]
4. [State answer clearly]
A: [Final answer]
Logic problems:
Q: [Premises and question]
Let's think through this:
- Premise 1: [State first fact]
- Premise 2: [State second fact]
- Therefore: [Logical conclusion]
A: [Answer]
Real-world reasoning:
Q: [Scenario-based question]
Analysis:
- Current situation: [Describe state]
- Relevant factors: [List considerations]
- Conclusion: [Reasoned answer]
A: [Final answer]
Examples and Use Cases
Solving Math Problems
Without CoT: Prompt: "If Sarah has 15 apples and gives 4 to John and 3 to Maria, how many does she have left?" Output: "Sarah has 8 apples left."
With CoT: Prompt: "If Sarah has 15 apples and gives 4 to John and 3 to Maria, how many does she have left? Let's work through this step by step." Output:
Starting amount: 15 apples
Gave to John: 4 apples
Remaining after John: 15 - 4 = 11 apples
Gave to Maria: 3 apples
Final amount: 11 - 3 = 8 apples
Answer: 8 apples
The reasoning chain catches errors. If the model miscalculates at any step, the mistake becomes visible rather than hidden in the final answer.
Question Answering and Reasoning Tasks
CoT helps when answers require connecting multiple facts: extract relevant info, link evidence, and conclude.
Example: Given a passage about historical events, answer "Why did X lead to Y?" CoT output shows: extracted fact 1, extracted fact 2, connection between facts, conclusion.
Content, Chatbots, Education
- Tutoring: Shows full problem-solving process.
- Content generation: Ensures logical flow.
- Support bots: Explicit reasoning builds trust and clarity.
Benefits of Chain of Thought Prompting
- Improves accuracy on complex tasks by 20–50%.
- Makes errors easier to detect.
- Increases transparency for users.
- Reduces hallucinations through step-by-step constraints.
Common Challenges
- Higher token usage → increased API costs.
- Reasoning chains may appear logical but contain subtle errors.
- Over-reasoning can make outputs unnecessarily verbose.
Effective Prompting Tips
- Set temperature 0-0.3 for consistent reasoning.
- Use numbered or bulleted steps to structure the chain.
- Include cues like "Let's think step by step".
- Specify output format: e.g., "Answer: [your answer]".
Reducing Hallucinations and Errors
- Apply self-consistency: generate multiple chains and compare answers.
- Constrain outputs to the provided context.
- Split long chains into smaller sub-problems for verification.
Frequently Asked Questions
What are the key steps in the chain of thought?
Every CoT prompt needs:
- Clear problem statement
- Intermediate reasoning steps
- Explicit final answer
What is the prompt chaining technique?
Prompt chaining connects multiple CoT prompts in sequence. The first prompt produces output that becomes input for the second prompt. This handles complex workflows by breaking them into manageable stages.
Example: summarize → analyze → recommend.
What models work best with chain of thought?
GPT-4, Claude 3, and Gemini 1.5 show the best CoT performance. Open-source models like Llama 3 70B work adequately. Models need 10B+ parameters for meaningful benefits. Smaller models show minimal improvement from CoT.
What is the chain of thought theory?
CoT theory draws from both cognitive psychology and machine learning. Humans solve complex problems by decomposing them into steps. Language models benefit from the same approach because it matches their token-by-token processing architecture. Each step in the chain provides context for subsequent reasoning.
When should I use CoT vs Regular Prompting?
- Use CoT: multi-step problems, math/logic, inference tasks, transparency needed.
- Use standard prompting: simple questions, tight token budget, recall tasks.
- Rule of thumb: if you can solve it mentally in one step, regular prompting suffices.
What if the model makes an error mid-chain?
Errors propagate through subsequent steps. Strategies include self-consistency, checkpointing, splitting tasks into smaller prompts, or regenerating from the error point. Programmatic verification is useful for calculations.
Does CoT work for creative tasks or only logical problems?
Yes. For writing, design, or content generation, CoT helps plan structure, brainstorm ideas, and make reasoning explicit before producing final output.
Example creative CoT:
Task: Write an engaging product description
Planning:
- Target audience: busy professionals
- Key benefit: time savings
- Tone: friendly but professional
- Structure: problem → solution → call to action
[Generate description following this plan]
How do I implement CoT in production API calls?
Example implementation:
import openai
def cot_prompt(problem):
return f"""
Solve this problem step by step:
{problem}
Let's work through this carefully:
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant that shows your reasoning."},
{"role": "user", "content": cot_prompt(user_question)}
],
temperature=0.2,
max_tokens=500
)
# Parse response
reasoning = response.choices[0].message.content
answer = extract_final_answer(reasoning)
Error handling: implement timeouts, validate reasoning structure, fallback to regular prompting if CoT fails.
What’s the optimal chain length?
Most problems work with 3–7 reasoning steps. Simple math: 3-4, logic: 4-6, complex analysis: 6-10. Beyond 10 steps, consider prompt chaining. Keep each step meaningful to avoid verbosity.
How do I use CoT for multi-turn conversations?
Maintain reasoning context across conversation turns. Store previous reasoning chains in conversation history. Reference earlier steps when building on previous reasoning.
Example pattern:
Turn 1: User asks question → Model provides CoT reasoning → Stores reasoning
Turn 2: User asks follow-up → Model references Turn 1 reasoning → Builds on previous steps
State management becomes critical. Track which parts of earlier reasoning remain relevant. Clear conversation state when context shifts to new topics.
Can I hide reasoning steps from users?
Backend reasoning with frontend filtering works well. Generate full CoT in your API call, extract the final answer, display only the answer to users.
Pattern:
full_response = generate_cot_response(question)
reasoning_steps = extract_steps(full_response)
final_answer = extract_answer(full_response)
# Log reasoning for debugging
log_reasoning(reasoning_steps)
# Show only answer to user
return final_answer
This maintains transparency for debugging while keeping UI clean. Some applications offer an "Show reasoning" toggle, letting users choose.
CoT vs ReAct Prompting: when to use which?
CoT is for reasoning using provided information. ReAct combines reasoning with external actions (API calls, searches). Choose CoT for closed-world tasks and ReAct for open-world or action-driven tasks.
How do I use CoT for classification vs generation tasks?
Classification CoT:
Text: [input]
Analysis:
- Key indicators: [features]
- Matches category X because: [reasoning]
Classification: X
Generation CoT:
Task: [generate content]
Planning:
- Structure: [outline]
- Key points: [ideas]
- Tone: [style]
[Generated content]
Classification CoT analyzes features leading to a label. Generation CoT plans structure before creating content. Both benefit from explicit reasoning but serve different purposes.
What if CoT makes my outputs too verbose for my use case?
Limit reasoning steps, use abbreviated CoT prompts, or summarize chains post-generation. Zero-shot CoT can reduce verbosity while retaining step-by-step reasoning.
Can I combine CoT with RAG?
Yes. RAG retrieves relevant information, and CoT reasons over it. This is effective for complex queries needing external knowledge and multi-step reasoning.
Does self-consistency improve accuracy?
Yes. Generating multiple reasoning paths and taking the majority reduces errors by 5–15%. It increases token usage 5–10x, so use for tasks where accuracy outweighs cost.
Getting Started
Zero-shot CoT prompts are a good starting point to test step-by-step reasoning. From there, you can add few-shot examples or self-consistency when tasks demand higher reliability. Tools like DSPy and Auto-CoT can help streamline prompt setup.
For more complex scenarios, consider combining CoT with external actions while keeping each step verifiable.
Focus on creating clear, structured reasoning chains that provide correct answers and remain auditable.
You can also connect to our experts to implement and optimize Chain of Thought workflows, ensuring reliable and auditable model outputs.