RAG Application Development Guide | All You Need to Know in 2026

Large language models know a lot, but they don't know everything. They can't access your internal documents, yesterday's sales reports, or the latest regulatory updates. Retrieval-Augmented Generation (RAG) solves this by connecting LLMs to external knowledge bases at runtime, grounding responses in your actual data.
According to Grand View Research, the RAG market reached $1.2 billion in 2023 and will grow at 49.1% CAGR through 2030. Enterprises are adopting RAG for 30-60% of their AI use cases, particularly where accuracy and transparency matter.
Let’s break down how RAG works, when it makes sense to use it, and what to consider when building and operating production-ready RAG systems.
What Is RAG Application Development?
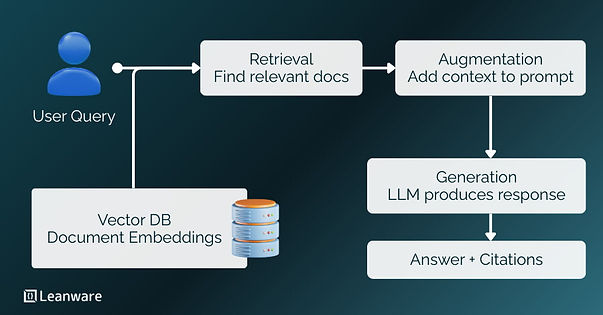
RAG combines information retrieval with text generation. When a user asks a question, the system first searches a knowledge base for relevant documents, then passes those documents to an LLM as context for generating a response.
Meta AI researchers introduced the concept in their 2020 paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” Rather than storing all knowledge inside model weights, the approach retrieves relevant information on demand from external sources and uses it during generation.
How RAG Differs from Traditional AI Development
Traditional LLM usage relies entirely on what the model learned during training. The model generates responses from its parameters, which means it can't access new information or private data.
RAG adds a retrieval step before generation. The architecture includes a knowledge base (your documents), a retrieval system (finds relevant content), and a generator (the LLM that produces responses using retrieved context).
This separation provides three advantages.
- First, you can update knowledge without retraining.
- Second, responses cite actual sources.
- Third, the model works with data it never saw during training.
How RAG Application Development Works
RAG connects a language model to an external knowledge base so responses rely on real, current data. Documents are indexed as embeddings in a vector database, and relevant chunks are retrieved at query time and added to the prompt, enabling accurate, domain-specific answers without retraining the model.
Step 1: Create and Index External Data Sources
RAG starts with your data. This might include internal documents, knowledge bases, product catalogs, support tickets, or any text corpus relevant to your use case.
The indexing process converts documents into vector embeddings, numerical representations that capture semantic meaning. Tools like LangChain, LlamaIndex, Pinecone, Weaviate, and ChromaDB handle this conversion and storage.
Chunking strategy matters here. Documents split into smaller segments (typically 256-512 tokens) enable more precise retrieval. Too large and you retrieve irrelevant content. Too small and you lose context.
Step 2: Retrieve Relevant Information at Runtime
When a query arrives, the system converts it to a vector embedding using the same model that indexed the documents. It then searches the vector database for the most similar document chunks.
Retrieval methods include dense retrieval (vector similarity search), sparse retrieval (keyword matching like BM25), and hybrid approaches that combine both. Dense retrieval excels at semantic understanding while sparse retrieval handles exact matches better.
Most production systems retrieve 3-10 chunks per query, balancing relevance against context window limits.
Step 3: Augment LLM Prompts with Retrieved Context
The retrieved documents become part of the prompt sent to the LLM. A simple pattern looks like this:
Without RAG:
User: What is our refund policy?
With RAG:
Context: [Retrieved policy document excerpts]
User: What is our refund policy?
The LLM generates a response grounded in the provided context rather than relying on generic training knowledge.
Step 4: Update and Maintain External Knowledge Bases
Knowledge bases require ongoing maintenance. Documents change, new content arrives, and old information becomes outdated.
Production systems implement update pipelines that detect document changes, re-embed modified content, and sync with the vector database. Tools like Apache Airflow or Prefect orchestrate these workflows. Version control for your knowledge base helps track what changed and when.
Key Benefits of RAG Application Development
RAG grounds language models in up-to-date data, reducing hallucinations and knowledge cutoff issues. It enables accurate, verifiable outputs without retraining and keeps proprietary data outside model weights, supporting security and compliance in regulated industries.
1. Improved Relevance and Accuracy
RAG grounds responses in actual documents, reducing hallucinations. When the model cites a specific policy or data point, that information exists in your knowledge base.
Research shows RAG improves factual accuracy significantly. One study found GPT-4 accuracy increased from 75% to 86% when RAG was added to a fine-tuned model.
2. Integration with Custom Enterprise Data
RAG accesses data the LLM never saw during training: internal wikis, proprietary research, customer records, and real-time information. This makes it practical for enterprise applications where generic model knowledge falls short.
3. Cost and Performance Advantages
RAG costs less than fine-tuning for most use cases. Fine-tuning requires labeled training data, computational resources for training runs, and periodic retraining as data evolves.
RAG uses existing data without modification. You build the retrieval pipeline once and update the knowledge base as needed.
According to Red Hat, RAG is typically more cost-efficient because it leverages existing data to inform the LLM without specialized data labeling or intensive model training.
4. Better Control Over Output Quality
You control what the model can reference. By curating the knowledge base, you manage response quality, remove outdated information, and ensure compliance with policies. This transparency helps in regulated industries where you need to audit what influenced a response.
Use Cases and Applications for RAG Development
RAG delivers the most value in scenarios where answers must be accurate, explainable, and tied directly to trusted data sources rather than general model knowledge.
Enterprise Search and Knowledge Management
RAG transforms how employees find information. Instead of keyword searches returning document lists, RAG provides direct answers with source citations.
Morgan Stanley built a RAG system using GPT-4 and their 100,000+ document knowledge base. According to OpenAI, over 98% of advisor teams now use the assistant, and salespeople respond to client inquiries in one-tenth the time compared to manual searches.
Intelligent Conversational Agents
Customer support chatbots benefit from RAG by accessing product documentation, troubleshooting guides, and policy details. The bot answers specific questions rather than deflecting to human agents.
Sales support agents use RAG to pull relevant case studies, pricing information, and competitive analysis during customer conversations.
Personalized Recommendation Systems
RAG enhances recommendation engines by incorporating contextual information beyond user history. The system retrieves relevant product details, reviews, or content to explain why something was recommended.
Regulated Domains (Legal, Finance, Healthcare)
High-stakes fields require traceable, accurate responses. RAG provides the citation trail that compliance teams need. When a financial advisor bot recommends an action, it can reference the specific regulatory guidance that supports that recommendation.
Challenges in RAG Application Development
RAG addresses knowledge limitations of LLMs but introduces engineering challenges that must be managed to maintain reliability and performance.
Challenge | Cause | Mitigation |
|---|---|---|
Noisy or incomplete data | Outdated, duplicated, or poorly formatted documents | Data cleaning, validation, regular audits |
Retrieval latency | Vector search adds overhead | Caching, ANN search, optimized infrastructure |
Scaling large corpora | Large search space reduces efficiency | Sharding, hybrid search, hierarchical indexing |
Handling Noisy or Incomplete Data
RAG quality depends on knowledge base quality. Garbage in, garbage out. Documents with errors, outdated information, or poor formatting produce unreliable responses.
Common data issues include duplicate content that skews retrieval, inconsistent formatting across document sources, missing metadata that prevents proper filtering, and stale information that contradicts current facts.
Data cleaning pipelines, regular audits, and source validation help maintain quality. Some teams implement confidence scoring to flag responses based on low-quality sources.
Latency and Retrieval Efficiency
RAG adds a retrieval step before generation, increasing response time. Vector searches, especially across large corpora, introduce latency that users notice.
Typical RAG pipelines add 100-500ms for retrieval depending on corpus size and infrastructure. For interactive applications, this matters.
Optimization strategies include caching frequent queries, using approximate nearest neighbor algorithms, pre-computing embeddings for common question patterns, and running vector databases on high-memory instances.
Scalability Across Large Corpora
Vector databases handle millions of documents, but performance degrades without proper architecture. Hierarchical indexing, sharding, and hybrid search approaches help maintain speed at scale.
Organizations with very large corpora often implement tiered retrieval: fast filtering followed by precise ranking. This reduces the number of vectors searched while maintaining accuracy.
RAG Reference Architecture and Best Practices
Building a robust RAG system requires more than just connecting an LLM to a vector database.
Core Components (Vector DB, Indexer, Retriever, LLM)
A production RAG system relies on modular components that each handle a specific role. Together, they ensure documents are ingested, searchable, and used effectively by the model.
Component | Purpose | Common Tools |
Document Store | Raw document storage | S3, GCS, database |
Indexer | Converts documents to embeddings | LangChain, LlamaIndex |
Vector Database | Stores and searches embeddings | Pinecone, Weaviate, ChromaDB, FAISS |
Retriever | Finds relevant documents | Semantic search, BM25, hybrid |
LLM | Generates responses | OpenAI, Anthropic, open-source models |
Orchestrator | Coordinates the pipeline | LangChain, custom code |
Data Pipeline and Update Strategy
Automated pipelines keep knowledge bases current. A typical workflow watches for document changes, processes new or modified files, generates embeddings, updates the vector database, and logs changes for audit.
Schedule regular full reindexes to catch drift and ensure consistency.
Security, Privacy, and Compliance Considerations
RAG systems access sensitive data, requiring proper controls. Implement encryption at rest and in transit, access controls that respect document-level permissions, audit logging for retrieval operations, and data residency compliance where required.
For HIPAA or GDPR scenarios, ensure the LLM provider's data handling meets requirements. Some organizations run models on-premise to maintain data sovereignty.
When to Use RAG vs. Other Customization Methods
Choosing the right approach depends on whether you need to change model behavior, inject new knowledge, or both. Let’s compare RAG with other common customization strategies.
RAG vs. Prompt Engineering
Prompt engineering adds instructions to guide model behavior but doesn't inject new knowledge. It works for formatting, tone, and simple task guidance.
RAG adds actual information the model doesn't have. Use prompt engineering for behavior changes, RAG for knowledge additions.
RAG vs. Fine-Tuning
Fine-tuning modifies model weights through additional training. It teaches the model new patterns, terminology, or response styles.
Factor | RAG | Fine-Tuning |
Setup Cost | Lower (build pipeline) | Higher (prepare training data, compute) |
Knowledge Updates | Easy (update documents) | Hard (retrain model) |
Latency | Higher (retrieval step) | Lower (direct generation) |
Best For | Factual accuracy, current data | Style, behavior, domain expertise |
Many production systems combine both: fine-tune for domain language and behavior, RAG for current factual content.
When Full Pre-Training Is Appropriate
Pre-training from scratch suits organizations building foundation models or requiring capabilities that don't exist in available models. This applies mainly to research labs and large tech companies. Most enterprises never need this level of investment.
Future of RAG in AI Development
RAG is becoming a standard approach for extending LLMs. According to K2View, 86% of organizations augmenting LLMs use RAG frameworks, recognizing that out-of-the-box models lack customization for specific business needs.
The technology continues evolving. Agentic RAG, where AI agents decide when and what to retrieve, represents the next frontier. Graph-based approaches like GraphRAG improve performance on complex reasoning tasks. Evaluation frameworks are maturing to help teams measure RAG quality systematically.
For teams evaluating RAG, start with a clear use case where factual accuracy matters, data exists but isn't in the model's training set, and response traceability adds value. Those conditions describe most enterprise AI applications.
Getting Started
RAG bridges the gap between general-purpose LLMs and domain-specific applications. Start by defining your knowledge sources, selecting appropriate tooling, and building a prototype with a focused use case.
The key decisions involve chunking strategy, retrieval method, and knowledge base maintenance. Get these right, and RAG delivers accurate, grounded responses that generic models can't match.
You can also reach out to our experts for guidance on evaluating RAG, designing retrieval pipelines, or integrating external data to ensure accurate and traceable AI outputs.
Frequently Asked Questions
What is RAG in AI?
RAG stands for Retrieval-Augmented Generation. It retrieves relevant documents from a knowledge base and includes them as context when generating LLM responses. This grounds outputs in actual data rather than relying solely on what the model learned during training
Is RAG better than fine-tuning?
It depends on your goal. RAG excels at factual accuracy and accessing current or private data. Fine-tuning works better for changing model behavior, style, or teaching domain-specific patterns. Many production systems use both together.
What tools are used in RAG development?
Common tools include LangChain and LlamaIndex for orchestration, Pinecone, Weaviate, and ChromaDB for vector storage, OpenAI or Anthropic APIs for generation, and embedding models for converting text to vectors.
Can RAG use private company data?
Yes. This is one of RAG's primary advantages. You index your internal documents, and the LLM references them without that data ever being part of model training.
What are the limitations of RAG?
Key limitations include retrieval quality dependency (bad data produces bad responses), added latency from the retrieval step, context window limits that constrain how much retrieved content the LLM can use, and maintenance overhead for keeping knowledge bases current.
How long does RAG development take?
Timelines vary by scope. An MVP using off-the-shelf tools takes 1-3 weeks. Production systems with optimized retrieval, security, and monitoring require 4-8 weeks. Enterprise implementations with compliance requirements, custom infrastructure, and system integrations take 2-4+ months.
What happens when RAG retrieves outdated or conflicting information?
The model may generate inaccurate responses. Mitigation strategies include version-stamped content, ranking logic that prioritizes trusted sources, regular data pipeline updates, and human-in-the-loop review for critical applications.