Retrieval-Augmented Decision Engines vs RAG: Arch & Use Cases
Many organizations have already adopted RAG for knowledge assistants, internal search tools, and documentation Q&A systems. Retrieval works, and the answers are usually grounded. Hallucinations are less frequent.
Problems arise when these systems need to go beyond providing answers. A support ticket needs routing, a loan application requires approval, a compliance check must produce a clear yes or no. Traditional RAG architectures provide information but do not produce consistent decisions.
Retrieval-Augmented Decision Engines address this gap. They build on RAG by adding reasoning layers, rule enforcement, and execution capabilities, turning retrieved knowledge into operational outcomes rather than text.
What Is Retrieval-Augmented Generation (RAG)?
RAG combines large language models with external knowledge retrieval. Instead of relying solely on what the model learned during training, RAG fetches relevant documents at inference time and injects them into the prompt. This grounds the response in actual data.
It follows a simple pattern: take a user query, search a knowledge base for relevant content, combine that content with the query, and generate a response. The retrieved context reduces hallucinations by giving the model factual material to reference rather than forcing it to recall information from parameters.
The architecture doesn't add decision logic. It adds context. The LLM still generates free-form text based on patterns it learned during training.
Typical RAG Architecture
A standard RAG pipeline includes:
- Query processing: The user's input gets converted to an embedding
- Retrieval: Vector similarity search finds relevant document chunks
- Context injection: Retrieved chunks get added to the prompt
- Generation: The LLM produces a response grounded in the retrieved content
Vector databases like Pinecone, Weaviate, or Chroma store the embeddings. The same embedding model used for indexing must process the query to ensure comparable vectors.
Common Use Cases Where RAG Works Well
RAG performs well on informational tasks with low operational risk:
- Internal knowledge assistants
- Documentation Q&A
- Research synthesis
- Customer support chatbots (informational queries)
- Content summarization
These use cases share a common trait: the output is text meant for human consumption. A human reads the response, evaluates it, and decides what to do next.
Key Limitations of Traditional RAG
RAG struggles when systems need to act, not just inform:
Non-determinism: The same query can produce different outputs across runs. For informational responses, this variability is acceptable. For operational decisions, it creates compliance and consistency problems.
No rule enforcement: RAG can't guarantee outputs conform to business policies. The LLM might generate a response that violates a constraint the organization needs to enforce.
Weak auditability: Tracing why a specific response was generated requires reconstructing the retrieval and generation process. There's no structured decision log.
No execution path: RAG produces text. It doesn't trigger workflows, update databases, or call APIs.
What Is a Retrieval-Augmented Decision Engine?

A Retrieval-Augmented Decision Engine produces structured, actionable outcomes rather than text. It takes inputs - data, context, or queries - retrieves relevant information, applies reasoning and rule-based logic, and generates decisions such as approve/reject, route to a queue, escalate to a human, or trigger a workflow. These outputs are auditable and executable.
RAG is one component within this system, responsible for retrieval and initial reasoning. Additional layers enforce rules, manage confidence thresholds, and determine the resulting actions.
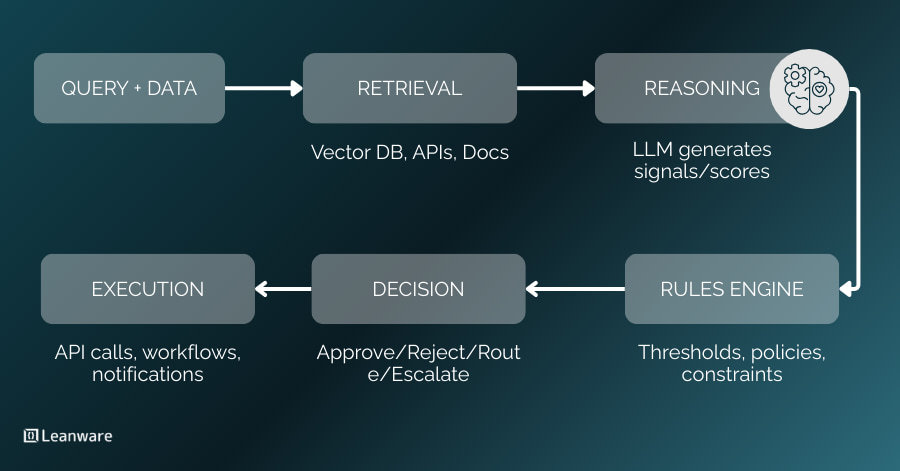
How Decision Engines Extend RAG
Decision Engines wrap RAG in additional architectural layers:
Layer | RAG | Decision Engine |
Retrieval | Vector search for relevant docs | Same, plus structured data, APIs |
Reasoning | LLM generates text | LLM generates signals/scores |
Rules | None | Policy constraints, thresholds |
Output | Free-form text | Structured decisions |
Execution | None | API calls, workflow triggers |
Logging | Basic | Full decision audit trail |
The LLM shifts from being the final output generator to being one reasoning component whose outputs get validated, constrained, and routed by deterministic logic.
Decision-Oriented Outputs vs Text-Based Outputs
RAG output: "Based on the policy documents, this claim appears to meet the criteria for expedited processing due to the documented pre-authorization."
Decision Engine output:
{
"decision": "approve",
"routing": "expedited_queue",
"confidence": 0.87,
"rules_applied": ["pre_auth_check", "amount_threshold"],
"requires_review": false
}
The first is helpful for a human. The second is actionable by a system.
RAG vs Retrieval-Augmented Decision Engines
RAG is designed to generate accurate, relevant text based on retrieved knowledge, while Retrieval-Augmented Decision Engines build on this approach to produce structured, auditable decisions that can trigger actions. The main distinction is that RAG informs humans, whereas Decision Engines are designed to drive operational outcomes reliably.
Purpose and System Goals
RAG aims to produce better answers by grounding generation in retrieved facts. The goal is accuracy and relevance in text output.
Decision Engines aim to produce consistent, correct decisions that can drive automated actions. The goal is operational reliability.
Output Types and Determinism
RAG outputs vary across runs because LLM generation is probabilistic. For Q&A, this is fine. For decisions that affect customers, finances, or compliance, variability becomes a liability.
Decision Engines constrain outputs through rules and thresholds. The LLM might produce a confidence score or classification signal, but the final decision passes through deterministic logic that ensures consistency.
Automation and Execution Capabilities
RAG systems typically end at the response. A human reads it and takes action.
Decision Engines connect to execution layers: APIs that update records, workflow systems that route tasks, notification services that alert stakeholders. The decision flows directly into operational systems.
Risk, Control, and Observability
RAG logging captures queries and responses. Debugging requires reconstructing what happened.
Decision Engines log every component: what was retrieved, what the reasoning layer produced, which rules fired, what decision resulted, what action executed. This audit trail supports compliance requirements and post-hoc analysis.
Architecture of a Retrieval-Augmented Decision Engine
A Retrieval-Augmented Decision Engine is built in layers: retrieval gathers information, reasoning interprets it, decision logic enforces rules, and execution carries out actions. Feedback and monitoring keep the system accurate, consistent, and improving over time.
Retrieval Layer
The retrieval layer gathers context from multiple sources:
- Vector databases for unstructured knowledge
- SQL databases for structured records
- APIs for real-time data (pricing, inventory, customer status)
- Document stores for policies and procedures
Hybrid search combining dense embeddings with keyword matching (BM25) improves retrieval precision. The layer must also handle freshness: some decisions require current data, not cached embeddings from last week's index.
Reasoning and Planning Layer
The LLM analyzes retrieved context and produces structured signals:
- Classification labels
- Confidence scores
- Extracted entities
- Risk assessments
This layer does not make the final decision. It generates inputs for the decision logic layer. Prompt engineering ensures outputs conform to expected schemas.
Decision Logic and Rule Enforcement
This layer applies business rules to reasoning outputs:
- Threshold checks (confidence > 0.8 for auto-approval)
- Policy constraints (amounts over $10K require manager review)
- Regulatory rules (geographic restrictions, eligibility criteria)
- Escalation triggers (low confidence routes to human)
Rules engines, scoring models, or simple conditional logic implement these constraints. The key: this layer is deterministic. Given the same inputs, it produces the same outputs.
Execution and Action Layer
Decisions trigger actions:
- API calls to update records
- Workflow triggers for downstream processes
- Notifications to stakeholders
- State changes in operational systems
This layer handles retries, error handling, and confirmation that actions completed successfully.
Feedback, Monitoring, and Evaluation Loops
Production Decision Engines require continuous monitoring:
- Decision distribution tracking (are approval rates shifting?)
- Confidence calibration (do 90% confidence decisions actually succeed 90% of the time?)
- Human override analysis (which decisions get reversed?)
- Latency and throughput metrics
Feedback loops improve the system over time. Human corrections become training signals. Edge cases inform rule refinements.
Why Some Decisions Should Not Be Solved with RAG Alone
RAG is useful for providing information, but it isn’t designed for high-stakes, repeatable decisions. When consistency, auditability, and compliance matter, relying solely on RAG can introduce risk.
High-Risk and High-Impact Decisions
Credit approvals, medical triage recommendations, compliance checks, and fraud assessments all carry real consequences if handled incorrectly.
A hallucinated response in a Q&A system is inconvenient; a wrong decision in these areas can lead to financial loss, regulatory issues, or operational problems.
Non-Deterministic Outputs in Critical Systems
Regulated industries need predictable results. If the same request is approved one day and rejected the next without changes to the underlying data, the system fails operational expectations.
RAG’s inherent variability makes it unsuitable as the sole mechanism for such decisions.
Auditability and Compliance Constraints
Regulators often require clear explanations for decisions. RAG systems struggle to provide definitive reasoning. Decision Engines, with layered rules and detailed logging, can produce audit trails showing what information was used, which rules applied, and how the final outcome was determined.
Industry Use Cases for Retrieval-Augmented Decision Engines
Decision Engines add structure and rules to AI workflows, making them suitable for industries where errors have real consequences. They turn retrieved knowledge into actionable, auditable outcomes across finance, healthcare, operations, customer support, and compliance.
Fintech and Financial Services
- Credit decisioning: Retrieve applicant history, apply scoring models, enforce policy thresholds, route to appropriate approval queue.
- Fraud detection: Analyze transaction patterns, retrieve account context, trigger holds or escalations based on risk scores
- Transaction routing: Determine processing paths based on amount, type, customer tier
Healthcare and Life Sciences
- Triage support: Retrieve symptom-condition mappings, assess urgency signals, route to appropriate care level.
- Clinical decision support: Surface relevant protocols, flag contraindications, ensure guideline compliance.
- Prior authorization: Retrieve coverage rules, assess request against policy, generate structured determinations.
Supply Chain and Operations
- Exception handling: Detect anomalies, retrieve historical patterns, trigger appropriate response workflows.
- Inventory decisions: Assess demand signals, apply reorder rules, generate purchase orders.
- Supplier evaluation: Aggregate performance data, apply scoring criteria, flag risk conditions.
Customer Support and Service Automation
- Ticket routing: Classify issue type, assess complexity, route to appropriate queue or agent.
- SLA enforcement: Monitor response times, trigger escalations, adjust priorities.
- Resolution recommendations: Retrieve similar cases, suggest solutions, track outcomes.
Legal, Compliance, and Risk Management
- Document classification: Analyze content, apply taxonomy rules, route for appropriate review.
- Policy compliance checks: Retrieve applicable regulations, assess against requirements, flag violations.
- Contract analysis: Extract key terms, compare against standards, identify risk clauses.
Governance, Safety, and Human-in-the-Loop Controls
Operational AI requires oversight. Confidence thresholds, human review, and detailed logging ensure that automated decisions remain safe, explainable, and continuously improving.
Confidence Thresholds and Escalation Rules
Not every decision should be automated. Confidence thresholds determine when systems act autonomously versus escalating to humans:
- High confidence + low risk = auto-execute
- High confidence + high risk = human verification
- Low confidence = human decision
These thresholds require calibration based on actual outcomes.
Human Review and Override Mechanisms
Even automated systems require override paths. Humans need the ability to reverse decisions, and those reversals should feed back into system improvement. Interfaces should support efficient review while capturing structured feedback.
Logging, Auditing, and Explainability
Every decision needs a complete record:
- Input data and retrieved context
- Reasoning layer outputs
- Rules evaluated and results
- Final decision and actions taken
- Timestamps and system versions
This logging supports debugging, compliance, and continuous improvement.
How to Evolve from RAG to a Decision Engine
Moving from a standard RAG setup to a full Decision Engine is best done in stages, gradually adding structure, rules, and execution capabilities.
Stage 1: Informational RAG Systems
Begin with safe, read-only use cases. Focus on building the retrieval infrastructure, validating the accuracy of results, and establishing baseline metrics. At this stage, the system only provides information - no automated actions.
Stage 2: Recommendation and Scoring Systems
Introduce confidence scores and structured suggestions. The system can recommend actions, but humans make the final decisions. This helps build trust and exposes edge cases without creating operational risk.
Stage 3: Rule-Guided Decision Systems
Add explicit business rules that constrain AI outputs. Combine AI-generated signals with deterministic policy logic to make decisions consistent and auditable. This layer ensures that outcomes follow defined standards and thresholds.
Stage 4: Automated Decision Execution
Enable actions based on the rules and AI signals, starting with low-risk decisions. Gradually expand automation as confidence grows, while keeping human oversight for high-stakes cases.
Common Design Mistakes When Building Decision Engines
Common issues like missing rules, limited logging, or weak human oversight can affect a Decision Engine’s reliability and auditability.
- Over-reliance on prompts: Prompts can't enforce business rules reliably. LLMs don't guarantee output formats or constraint adherence.
- Missing rules layer: Skipping deterministic validation means accepting LLM variability in operational decisions.
- Insufficient observability: Without comprehensive logging, you can't debug failures or demonstrate compliance.
- Skipping human-in-the-loop design: Automated systems need override mechanisms. Building them as an afterthought creates poor user experiences.
- Ignoring calibration: Confidence scores mean nothing without validation against actual outcomes.
Your Next Step
RAG solves the grounding problem; Decision Engines handle actions. If you want your AI to do more than provide answers, you need layers for rules, execution, logging, and feedback.
If you’re already using RAG, you can build on it to create systems that not only inform but also make and carry out decisions. The setup is more complex, but it gives your operations real, measurable value.
You can also connect to our team for guidance on decision engine architecture, RAG implementation, or building production-ready AI systems.
Frequently asked questions
What is the difference between RAG and a Retrieval-Augmented Decision Engine?
RAG retrieves relevant knowledge and generates grounded text for humans to read. A Retrieval-Augmented Decision Engine goes further by producing structured, deterministic decisions (approve/reject, route/escalate, trigger workflows) that systems can execute automatically and audit reliably.
Why isn’t traditional RAG enough for automated decision-making?
RAG is non-deterministic and text-based. While this is acceptable for informational use cases, it creates risk for operational decisions that require consistency, rule enforcement, auditability, and compliance. Decision Engines add deterministic logic, confidence thresholds, and execution layers to address these gaps.
When should an organization move from RAG to a Decision Engine?
When AI outputs need to drive actions rather than inform humans. Examples include ticket routing, credit approvals, compliance checks, SLA enforcement, and workflow automation. If inconsistent answers or lack of traceability create business risk, it’s time to evolve beyond RAG.
How do Decision Engines ensure auditability and compliance?
Decision Engines log every step: retrieved context, reasoning outputs, rules evaluated, final decisions, and actions taken. This creates a complete audit trail that supports regulatory requirements, debugging, and post-hoc analysis - something RAG systems struggle to provide.
Can Decision Engines still include humans in the loop?
Yes. Human-in-the-loop controls are a core design element. Confidence thresholds determine when decisions are automated versus escalated, and human overrides are captured as feedback signals to improve future decisions while maintaining safety and accountability.