Guardrail ML – How to Implement Effective Guardrails for LLMs

Large language models generate useful content, but they also generate problems: hallucinated facts, leaked personal data, biased outputs, and responses to prompts they should refuse. Guardrail ML addresses these risks by adding safety controls that monitor and filter what goes into and comes out of LLM applications.
If you're deploying generative AI in production, especially in regulated industries or customer-facing products, guardrails are part of the infrastructure.
Let's explore what guardrail ML means, how it works, the main types of controls, and how to implement them effectively.
What Is Guardrail ML?
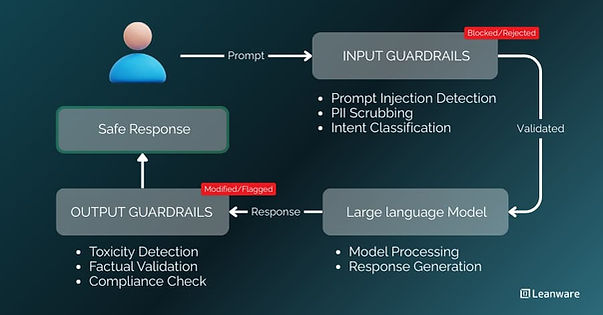
Guardrail ML refers to the safety mechanisms that guide LLM behavior in real time. These are validation layers, filters, and monitoring systems that sit between users and models to catch problematic inputs and outputs before they cause harm.
Unlike traditional software where behavior is deterministic, LLMs are probabilistic. The same prompt can produce different outputs. The model might follow instructions correctly or veer into fabricated claims, toxic language, or data it shouldn't expose. Guardrails impose boundaries on this unpredictable behavior.
How Guardrails Work with Large Language Models
Guardrails operate at multiple points in the LLM workflow:
Before the model (input guardrails): The system analyzes user prompts before they reach the model. It checks for prompt injection attacks, strips personally identifiable information (PII), and blocks requests that violate policy.
After the model (output guardrails): The system evaluates generated responses before returning them to users. It scans for hallucinations, toxic content, data leaks, and compliance violations.
During inference (model-level guardrails): Some controls operate within the model layer itself, such as system prompts that constrain behavior, temperature settings that affect randomness, or fine-tuning that shapes responses.
A typical flow looks like this:
- User submits prompt
- Input guardrails scan and validate the prompt
- Validated prompt goes to LLM
- LLM generates response
- Output guardrails evaluate the response
- Filtered response returns to user
If any guardrail flags an issue, the system can block the request, modify the output, request regeneration, or escalate for human review.
Guardrail ML vs Traditional ML Safety Controls
Traditional ML safety focused on model training: cleaning datasets, labeling data correctly, testing for bias before deployment, and reviewing outputs manually after the fact. These methods assumed you controlled the inputs and could predict the output space.
Generative AI breaks those assumptions. Users provide arbitrary natural language inputs. The output space is essentially infinite. Manual review doesn't scale when your model handles thousands of requests per minute.
Guardrail ML responds to this shift with real-time, context-aware controls that operate at inference time. Instead of hoping the model was trained well enough, guardrails actively monitor and intervene during every interaction.
Key Benefits of Guardrail ML
Ensuring Compliance, Reducing Bias, and Improving Trust
Regulated industries face specific requirements for AI systems. Healthcare applications must protect patient data under HIPAA. Financial services need audit trails and explainability. GDPR requires controls over personal data processing.
Guardrails help meet these requirements by:
- Detecting and redacting PII before it enters the model.
- Logging all inputs and outputs for audit purposes.
- Blocking responses that could constitute regulated advice (medical, legal, financial) without proper disclaimers.
- Filtering outputs that reflect demographic bias.
Trust also depends on consistency. Users lose confidence when an AI assistant occasionally produces inappropriate or factually wrong responses. Guardrails reduce variance by catching edge cases the model handles poorly.
Safeguarding Against Hallucinations, Data Leaks, and Adversarial Prompts
Hallucinations: LLMs generate plausible-sounding but false information. They cite nonexistent sources, invent statistics, and state incorrect facts with confidence. Output guardrails can cross-reference claims against knowledge bases, flag responses with low confidence scores, or require citations for factual statements.
Data leaks: Models trained on sensitive data might reproduce it. A model fine-tuned on customer support transcripts could leak customer information. Input guardrails prevent sensitive queries, and output guardrails scan for patterns matching protected data formats (credit card numbers, SSNs, API keys).
Adversarial prompts: Users deliberately craft inputs to bypass safety measures. Prompt injection attacks embed hidden instructions. Jailbreaks use social engineering to override system prompts. Input guardrails detect known attack patterns and anomalous prompt structures.
Main Types of Guardrail ML
1. Input-Level Guardrails
These filter user prompts before they reach the model:
Prompt injection detection: Identifies attempts to override system instructions. Attackers might include text like "ignore previous instructions and..." or embed instructions in seemingly innocent content. Detection methods include pattern matching, classification models trained on injection examples, and semantic analysis.
PII scrubbing: Removes or masks personal information from prompts. Users sometimes include sensitive data without realizing it. Scrubbing protects both the user and prevents the model from processing data it shouldn't have.
Intent classification: Determines what the user is trying to accomplish. Some intents may be out of scope or prohibited. A customer service bot might block requests for competitor information or attempts to extract proprietary data.
Content policy enforcement: Blocks prompts requesting harmful content: instructions for illegal activities, hate speech generation, or content involving minors. This layer applies organizational and legal policies before the model processes anything.
2. Output-Level Guardrails
These evaluate generated responses before delivery:
Toxicity detection: Scans for offensive language, hate speech, harassment, and other harmful content. Commercial APIs (OpenAI Moderation, Perspective API) and open-source classifiers can score outputs on multiple toxicity dimensions.
Factual validation: Compares claims against trusted sources. For high-stakes applications, responses can be checked against knowledge bases, and unsupported claims can be flagged or removed.
Compliance checking: Ensures outputs meet regulatory requirements. Financial applications might require risk disclaimers. Healthcare applications might need to avoid diagnostic language. Custom rules match outputs against compliance policies.
Format validation: Verifies that structured outputs (JSON, code, specific formats) conform to expected schemas. This catches malformed responses that could break downstream systems.
3. Model and Infrastructure-Level Guardrails
These operate at the backend:
Access control: Restricts which users or applications can access specific models or capabilities. Different user tiers might have different content policies or rate limits.
Logging and monitoring: Records all interactions for audit, debugging, and improvement. Monitoring detects anomalies: unusual query volumes, new attack patterns, or degraded response quality.
Rate limiting: Prevents abuse by capping request frequency. This protects against automated attacks and controls costs.
Dynamic policy switching: Adjusts guardrail strictness based on context. A children's education app needs stricter filters than an internal developer tool. Policies can vary by user, time, or application state.
How Guardrail ML Works in Practice
Architecture and Workflow
A production guardrail system typically includes:
- Preprocessing layer: Receives raw user input. Applies input guardrails (injection detection, PII scrubbing, intent classification). Rejects or modifies problematic inputs.
- Model layer: Processes validated prompts. It may include system prompts that constrain behavior and model configurations that affect output characteristics.
- Postprocessing layer: Receives raw model output. Applies output guardrails (toxicity scoring, factual validation, compliance checking). Filters, modifies, or regenerates responses as needed.
- Logging layer: Records inputs, outputs, guardrail decisions, and metadata. Feeds monitoring dashboards and audit systems.
- Feedback loop: Flagged outputs and user feedback inform guardrail improvements. Red team findings update detection rules.
Tools, Frameworks, and Best Practices
The guardrail tooling options have matured significantly. Here are the main options:
Guardrails AI: Open-source framework with a Hub of pre-built validators for toxicity, PII detection, competitor mentions, hallucination, and more. In February 2025, they launched the Guardrails Index, a benchmark comparing 24 guardrails across 6 categories. Supports both input and output guards with configurable failure actions.
NeMo Guardrails (NVIDIA): Open-source toolkit now available as NIM microservices optimized for NVIDIA GPUs. Includes three specialized NIMs for content safety, topic control, and jailbreak detection. Supports five rail types: input, output, dialog, retrieval, and execution. Recent updates added LangGraph integration for multi-agent workflows and support for reasoning models like Nemotron and DeepSeek-r1. Integrates with Llama Guard, ShieldGemma, Presidio for PII, and third-party services like ActiveFence and Clavata AI.
Fiddler Guardrails: Enterprise-focused solution handling 5+ million requests per day with latency under 100ms. Scores hallucination and safety metrics through a secure inference layer. Deploys in VPC and air-gapped environments for regulated industries.
DeepEval: Open-source library focusing on LLM guardrails with latency optimization. Uses LLM-as-a-judge for scoring while balancing speed and accuracy. Covers data leakage, prompt injection, jailbreaking, bias, and toxicity.
Databricks Guardrails: Native integration with Foundation Model APIs. Includes content safety categories out of the box and supports custom guardrails through Feature Serving. Integrates with Inference Tables and Lakehouse Monitoring for tracking safety over time.
Cloud Provider Options:
- Amazon Bedrock Guardrails: Managed service for content filters, denied topics, and PII handling.
- Azure AI Prompt Shield: Microsoft's guardrail for prompt injection and content safety.
- OpenAI Moderation API: Free endpoint classifying text for hate, violence, self-harm, and other categories.
Best practices across tools:
- Layer multiple guardrails rather than relying on one.
- Use both rule-based (regex, keyword) and ML-based detection.
- Keep guardrail logic separate from application code.
- Version control guardrail configurations.
- Monitor false positive and false negative rates.
- Reference OWASP Top 10 2025 for LLMs as a compliance baseline.
Implementing Guardrail ML Successfully
Designing Your Guardrail Strategy and Governance Model
Start by identifying your risk areas:
- What types of harmful outputs could your application produce?
- What data should never appear in inputs or outputs?
- What regulatory requirements apply to your use case?
- What would constitute a serious incident?
Map these risks to specific guardrail types. A healthcare application might prioritize PII protection and medical misinformation filtering. A code generation tool might focus on preventing malicious code and protecting proprietary algorithms.
Assign ownership. Someone needs to maintain guardrail rules, review flagged content, and update policies. This often spans engineering, legal, and product teams.
Document your policies. Write down what's allowed, what's prohibited, and what requires human review. These documents inform guardrail configuration and provide defensible rationale for decisions.
Testing, Monitoring, and Iterating Your Guardrail Setup
Red teaming: Before launch, attempt to break your guardrails. Try known prompt injection techniques. Test edge cases. Hire external testers who don't know your system's architecture. Document findings and update guardrails.
A/B testing: Compare guardrail configurations. Stricter rules reduce risk, but may degrade user experience by blocking legitimate requests. Measure false positive rates and user satisfaction alongside safety metrics.
Monitoring: Track guardrail triggers in production. High block rates might indicate overly strict rules or an attack. Low block rates might mean guardrails aren't catching issues. Set alerts for anomalies.
Feedback integration: Users who receive blocked or modified responses may complain. Review these complaints. Some indicate guardrail errors to fix. Others validate that guardrails are working.
Continuous improvement: Adversaries evolve their techniques. New risks emerge. Update guardrail rules regularly based on monitoring data, red team findings, and industry threat intelligence.
Building Responsible AI with Guardrails
Guardrail ML is one component of responsible AI, not a complete solution. It addresses runtime risks but doesn't replace thoughtful model selection, training data curation, bias testing, or transparent communication with users about AI limitations.
Effective guardrails require ongoing investment. Initial implementation is just the start. Maintenance, monitoring, and improvement need dedicated resources.
Start by assessing your current exposure. Identify where guardrails would reduce risk in your existing LLM applications. Evaluate tools that fit your stack. Implement in stages, starting with highest-risk areas. Build monitoring from day one so you can measure effectiveness and iterate.
The goal isn't perfect safety, which doesn't exist. The goal is systematic risk reduction that matches your application's requirements and your organization's risk tolerance.
Your Next Step
Audit your current LLM application for the risks that matter most: prompt injection, PII exposure, hallucinations, or off-topic responses. Pick one guardrail tool that fits your stack, implement input and output filters for your highest-risk area, and set up logging from day one.
Start with a single guardrail, measure its false positive rate, then expand coverage based on what you learn in production.
You can also connect with our experts to review your LLM setup and get guidance on implementing guardrails effectively.
Frequently Asked Questions
What is Guardrail ML in generative AI?
Guardrail ML refers to safety controls that monitor and filter LLM inputs and outputs in real time. These include prompt validation, output scanning, content policy enforcement, and logging systems that catch problematic content before it reaches users or causes harm.
Why do we need guardrails for LLMs?
LLMs are probabilistic and can produce hallucinations, toxic content, biased outputs, or leak sensitive information. They're also vulnerable to adversarial prompts designed to bypass safety measures. Guardrails reduce these risks at inference time when the model is actually serving users.
How do input-level and output-level guardrails differ?
Input-level guardrails filter user prompts before they reach the model. They detect prompt injections, remove PII, and block prohibited requests. Output-level guardrails evaluate model responses before returning them to users. They scan for toxicity, validate facts, check compliance, and ensure format correctness.
What are some examples of Guardrail ML tools?
Guardrails AI provides output validation. NeMo Guardrails offers programmable conversation safety. Rebuff specializes in prompt injection detection. OpenAI Moderation API scores content for harmful categories. Amazon Bedrock Guardrails provides managed filtering for Bedrock models. LangChain includes moderation chains for integration.
Can Guardrail ML prevent AI hallucinations?
Guardrails can reduce hallucinations by flagging low-confidence outputs, cross-referencing claims against knowledge bases, and requiring citations. However, they're not foolproof. Subtle factual errors may pass through, especially in domains without comprehensive verification sources. Guardrails lower the rate of hallucinations reaching users but don't eliminate them.
Is Guardrail ML the same as responsible AI?
No. Guardrail ML is a technical implementation focused on runtime safety. Responsible AI is a broader framework covering model selection, training data ethics, bias testing, transparency, accountability, and governance. Guardrails are one tool within responsible AI practices.
How do I start implementing guardrails in my AI application?
Begin with risk assessment: identify what could go wrong and what data needs protection. Select tools matching your stack and risk profile. Implement input guardrails first, since they prevent bad prompts from consuming model resources. Add output guardrails for response filtering. Set up logging and monitoring from the start. Test with red teaming before launch. Plan for ongoing maintenance and updates.