Prompt Engineering Evaluation Metrics: How to Measure Prompt Quality
Prompt engineering has evolved from an experimental practice into a structured discipline within large language model (LLM) development. As enterprises scale AI adoption, the reliability and efficiency of prompts directly affect product quality, user trust, and cost. Evaluating prompts is no longer optional; it is essential to ensure that AI systems perform as intended, remain factual, and respond consistently.
This guide explains how to measure prompt quality using established metrics, practical workflows, and tools used by leading AI teams.
Why Evaluate Prompt Engineering?
Evaluating prompts gives structure to what was once trial and error. It turns intuition into measurable performance, helping teams identify what works, what doesn’t, and why.
The Role of Prompts in LLM Performance
Prompts are the invisible interface between human intent and machine reasoning. Their structure, context, and clarity define how effectively a model interprets a request. Even small phrasing changes can alter output quality, factual accuracy, and tone. Because LLMs are sensitive to wording, testing prompts systematically is crucial for achieving predictable and reproducible behavior.
Benefits of Metrics-Driven Prompt Optimization
Quantifying prompt performance allows teams to make decisions based on evidence rather than guesswork. Evaluated prompts lead to improved model accuracy, fewer hallucinations, and lower token costs. Integrating metrics into development cycles also supports continuous optimization in ML and AI-Ops workflows—turning prompt iteration into a repeatable engineering process.
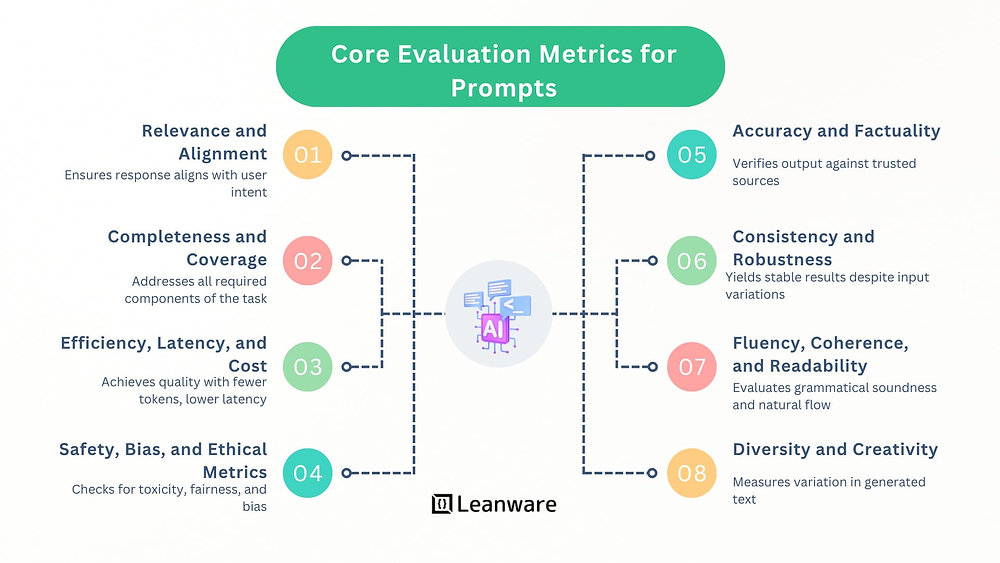
Core Evaluation Metrics for Prompts
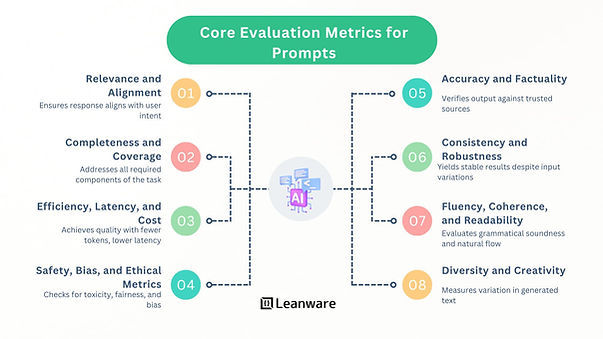
Prompt evaluation uses multiple dimensions. Not every metric applies to every task, but together they form a reliable framework for assessing both technical performance and user-perceived quality.
Accuracy and Factuality
Accuracy measures how well model outputs align with verifiable facts. In retrieval or QA tasks, outputs should be grounded in trusted sources or reference documents. Many teams now employ fact-checking layers or grounding APIs to verify whether responses cite valid data.
Relevance and Alignment
Relevance ensures that a model’s response stays on topic and aligns with the user’s intent or predefined task constraints. For example, in summarization tasks, relevance checks whether the model highlights key points rather than paraphrasing irrelevant details. Alignment extends this to ensure ethical and policy compliance.
Consistency and Robustness
A strong prompt should yield stable results even when inputs vary slightly. Evaluating consistency involves testing paraphrased or reordered prompts and observing whether responses stay semantically equivalent. Robustness tests guard against adversarial or ambiguous phrasing that might confuse the model.
Completeness and Coverage
Complex prompts often require multi-step reasoning. Completeness measures whether the model addresses all required components of a question or task. Coverage analysis is particularly useful in structured outputs, ensuring that each field or section is properly generated.
Fluency, Coherence, and Readability
For generative outputs like blogs or summaries, human readability matters as much as correctness. Fluency metrics evaluate grammatical soundness and natural flow, while coherence measures how logically connected ideas are. User satisfaction studies often include readability scores such as Flesch-Kincaid or human-rated coherence scales.
Efficiency, Latency, and Cost
Every token generated has an operational cost. Evaluating prompts for efficiency focuses on achieving the same quality with fewer tokens or lower latency. Monitoring average response time and cost per request is key for scaling production systems responsibly.
Diversity and Creativity
Creative prompts—such as for marketing copy or brainstorming—benefit from output diversity. Metrics like distinct-n or entropy can measure variation in generated text. Decoding strategies such as top-p sampling or temperature tuning are typically evaluated here to balance novelty with relevance.
Safety, Bias, and Ethical Metrics
Evaluation should include safety checks for toxicity, fairness, and bias. Tools such as OpenAI’s moderation API or Google’s Perspective API can flag unsafe content. Periodic bias audits help ensure responses do not unintentionally reinforce stereotypes or produce discriminatory results.
Categories of Evaluation Methods
Different methods serve different evaluation goals. A balanced pipeline usually combines automated and human approaches.
Reference-Based Metrics (BLEU, ROUGE, etc.)
These metrics compare model outputs to a reference dataset. BLEU and ROUGE are common for translation and summarization, measuring word overlap or sequence similarity. While they are objective and reproducible, they can undervalue creative or paraphrased answers.
Intrinsic or Model-Based Evaluation
Intrinsic metrics evaluate prompts using internal model probabilities such as log-likelihood or perplexity. Lower perplexity often indicates higher fluency or a better fit. This approach is especially useful for ranking prompt variations without external labels.
Human or Qualitative Evaluation
Human feedback remains the gold standard for tasks requiring nuance, emotion, or creativity. Teams may score prompts based on clarity, correctness, and engagement using a rubric. Structured annotation workflows with multiple reviewers help reduce subjectivity.
Prompt-Based Evaluator (LLM as Critic)
A growing trend is using an LLM to evaluate another LLM. Models like GPT-4 or Claude can be prompted to assess relevance, factuality, or tone. This method—known as “LLM-as-judge”—offers scalable evaluation, especially when labeled data is scarce. It’s related to Reinforcement Learning from AI Feedback (RLAIF), where AI models help refine prompts through iterative self-critique.
Example Workflow: Evaluating a Prompt from Start to Finish
Turning theory into practice involves following a structured workflow from goal definition to real-world testing.
Define Prompt, Objective, and Benchmark
Begin by defining what success looks like. For instance, “improve summarization accuracy by ten percent compared to baseline.” Establish a benchmark prompt that serves as the control version.
Choose Relevant Metrics and Baseline
Select metrics from the previous section that best fit your task. A summarization PoC might prioritize ROUGE and factuality, while a code-generation task might track execution accuracy or Pass@k rates.
Generate Candidate Outputs and Score Them
Run multiple prompt versions through the model and record results. Combine automatic scoring with human review for balanced insight. Tools such as OpenAI Evals or EleutherAI Eval Gauntlet can automate scoring pipelines.
Analyze Results and Identify Weaknesses
Look for consistent error patterns such as missing sections, verbosity, or hallucinations. Classifying these patterns builds an error taxonomy that guides the next iteration.
Refine Prompt and Iterate
Adjust prompt phrasing, structure, or examples. Techniques like prompt chaining or switching from zero-shot to few-shot formats often yield measurable gains.
A/B Testing and Real-World Monitoring
Deploy top-performing prompts in production and monitor real-user interactions. Track long-term engagement, satisfaction, and performance drift over time to ensure results remain stable.
Tools and Frameworks for Prompt Evaluation
A growing ecosystem of open-source and commercial tools makes prompt evaluation easier to automate and visualize.
Prompt Analytics and Logging Platforms
Platforms such as Langfuse, PromptLayer, and Helicone provide logging, version tracking, and real-time analytics. They allow teams to view performance metrics, analyze user behavior, and trace outputs back to specific prompt versions.
Evals Libraries and Metric Suites
Frameworks like OpenAI Evals, EleutherAI Eval Gauntlet, and TRuE Benchmark offer reusable evaluation templates for tasks like summarization, question answering, or reasoning. These libraries standardize testing and make comparisons across teams reproducible.
Custom Dashboarding and Monitoring
Many organizations build internal dashboards in Python or BI tools such as Tableau or Power BI. This allows integration with logs, metrics, and cost data for continuous monitoring within enterprise pipelines.
Challenges and Best Practices in Prompt Evaluation
While metrics bring rigor, they also introduce new complexities.
Metric Tradeoffs and Prioritization
Not all metrics carry equal weight for every use case. A chatbot might value fluency and latency over factual precision, while a research summarizer prioritizes accuracy. Defining metric priorities early prevents over-optimization.
Mitigating Human Bias in Judgments
Human evaluators introduce subjective bias. Use blind reviews, diverse annotator groups, and inter-rater agreement scoring to reduce skewed outcomes. Training evaluators on shared rubrics ensures consistency.
Overfitting to Metrics and Metric Gaming
Chasing high scores can lead to rigid or unnatural prompts. Remember that metrics are proxies for quality, not the goal itself. Validate performance with real users to prevent overfitting.
Continuously Adapting Metrics Over Time
As models evolve, your evaluation methods must too. Periodically revisit chosen metrics to align with new architectures, updated capabilities, and shifting organizational goals.
You can consult with our team to evaluate your project needs and identify the most effective approach.
FAQs
How to evaluate the effectiveness of an engineering prompt?
Effectiveness depends on measurable outcomes. Evaluate prompts against task-specific metrics such as accuracy, factuality, and user satisfaction. Continuous feedback loops from users help confirm whether improvements translate into real-world gains.
How do you measure accuracy in prompt engineering?
Accuracy is measured by comparing the model’s output against verified reference data or human-labeled ground truth. For example, in a QA system, factual consistency between generated answers and source documents is the core indicator.
What are objective metrics for prompt engineering?
Objective metrics include BLEU, ROUGE, and BERTScore for text similarity, as well as latency, token cost, and factual consistency for production evaluation. Combining multiple indicators provides a balanced view of quality and performance.
What is “eval” in prompt engineering?
An “eval” is a structured test used to measure how well a prompt performs on a specific task. Evaluations can be automated using metric suites or conducted manually through human scoring.
Can I evaluate prompts without ground truth data?
Yes. When no labeled dataset exists, you can use comparative scoring, LLM-as-judge evaluations, or human pairwise preferences. These methods provide proxy measures of quality and are common in creative or exploratory tasks.
What metrics matter most for RAG applications specifically?
For retrieval-augmented generation (RAG), focus on context relevance, citation accuracy, and faithfulness to retrieved sources. Evaluate how well the prompt encourages the model to quote or paraphrase correctly from retrieved documents
How do I integrate prompt evaluation into CI/CD pipelines?
Treat prompt evaluation like automated testing. Use frameworks such as OpenAI Evals or Eval Gauntlet, set quality gates for each release, and trigger evaluations through CI tools like GitHub Actions or Jenkins. Log metrics and attach them to prompt versions for traceability.
BLEU vs ROUGE vs BERTScore — when should I use each one?
Use BLEU for translation tasks that emphasize exact n-gram overlap, ROUGE for summarization where recall matters most, and BERTScore when semantic similarity is more important than surface wording. Combining them often provides the clearest signal.
What’s the minimum dataset size for reliable evaluation?
A good baseline is at least 100–200 samples for small tasks and 500+ for generalization testing. When data is limited, apply bootstrapping or confidence-interval analysis to estimate reliability.
How do I evaluate prompts when the “correct” answer is subjective?
For creative or stylistic tasks, design clear rubrics with multiple reviewers. Use pairwise preference scoring or majority voting to measure consensus and avoid over-relying on any single judgment.
What does a prompt evaluation pipeline look like in actual code?
A basic Python pipeline includes data loading, prompt execution, metric computation, and logging. Frameworks such as OpenAI Evals provide templates for running batch evaluations and exporting results to dashboards.
GPT-4 as evaluator vs Claude as evaluator — which is more reliable?
Both are strong, but reliability depends on the task type. GPT-4 is often more consistent for reasoning and factuality checks, while Claude performs well on stylistic or ethical evaluations. Cross-checking both can reduce bias.
Can I evaluate multi-turn conversation prompts differently?
Yes. Multi-turn evaluation requires tracking coherence and context retention across sessions. Conversation-level metrics such as topic continuity and memory consistency are better suited than single-turn scoring.
How do I evaluate prompts for code generation tasks specifically?
Code evaluation uses metrics such as execution correctness, syntax validity, and test pass rates. Benchmarks like HumanEval and Pass@k are standard for measuring output quality and reliability.
What if my automatic metrics disagree with human judgment?
Discrepancies happen because metrics capture surface patterns while humans evaluate meaning. Analyze cases of disagreement to refine metrics or weighting schemes. Human validation should always remain part of the process.
How do I version control prompts alongside evaluation scores?
Store prompts and their corresponding scores in version control using Git or DVC. Tag each commit with evaluation metadata and link it to model versions or deployment branches for full traceability.
How much does it cost to run comprehensive prompt evaluations?
Costs depend on task volume, model pricing, and automation level. Small-scale evaluations may cost under $50 using API credits, while enterprise-level continuous monitoring can reach several thousand dollars per month. Efficient batching and caching reduce expenses significantly.