Multi-Modal RAG Systems: Architecture, Costs, and Trade-Offs

Text-only RAG breaks when the answer lives in a diagram, a screenshot, or an audio recording. You can run OCR on images and transcribe audio, but you lose the visual relationships in charts and the speaker diarization that tells you who said what on a call.
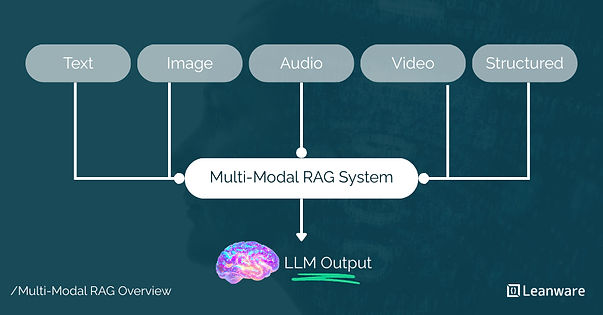
Multi-modal RAG handles text, images, audio, and video in the same retrieval pipeline.
The hard part isn't getting it to work in a notebook. The hard part is deploying it when video frame sampling at 3 FPS costs you three times more than 1 FPS, when adding image retrieval pushes your query latency from 500ms to 1.2 seconds, and when upgrading your embedding model means re-encoding 100,000 images before you can switch over.
Let’s explore how production multi‑modal RAG systems handle architecture, cost, latency, and real-world operational challenges.
Why Multi-Modal Context Matters in RAG Systems
Multi-modal context is critical because a significant portion of enterprise knowledge exists outside plain text. Technical diagrams, charts, screenshots, video demonstrations, and recorded audio often contain structured information or relationships that text extraction alone cannot capture.
Text-only RAG can retrieve paragraphs, but it cannot reason over visual layouts, temporal audio cues, or combined modalities.
Multi-modal RAG systems address these limitations by creating modality-specific embeddings and cross-modal retrieval strategies. This ensures the system retrieves not just textual matches, but contextually meaningful evidence across all relevant data types, which improves answer relevance, reasoning accuracy, and operational reliability in production environments.
What Is a Multi-Modal RAG System?
Multi-modal RAG extends standard retrieval-augmented generation to handle text, images, audio, video, and structured data within a unified retrieval pipeline. The system must support three mandatory components:
- Multi-modal ingestion processes different data types through modality-specific pipelines that normalize inputs into embeddable formats.
- Cross-modal retrieval searches across modalities using a shared or aligned embedding space where text queries can retrieve images and vice versa.
- Unified reasoning combines retrieved context from multiple modalities into a single generation step.
How Multi-Modal RAG Extends Retrieval-Augmented Generation
Standard RAG splits documents into text chunks, embeds them, stores vectors, and retrieves relevant chunks for LLM context. Multi-modal RAG adds modality-specific preprocessing pipelines before embedding and implements cross-modal alignment to enable queries in one modality to retrieve results from others.
What stays the same: the retrieve-then-generate pattern and vector similarity search. What changes: preprocessing complexity, embedding dimensionality, storage requirements, and the need for cross-modal alignment.
Modalities Supported in Multi-Modal RAG Systems
Each added modality increases infrastructure cost, query latency, and evaluation complexity. Text, images, audio, video, and structured data all require separate preprocessing, embeddings, and retrieval, with accuracy measured per modality.
Text-Based Knowledge Sources
Text remains the fallback modality because it's cheap to embed and retrieve. Typical chunk sizes range from 512 to 1024 tokens with overlap of 10-20%. Metadata stored includes document source, page number, section headers, and timestamps.
Text embeddings cost $0.02 per million tokens using models like OpenAI's text-embedding-3-small, making text the most cost-effective modality to scale.
Image and Visual Data
Images are represented through embeddings generated by vision models like CLIP, which projects images into a 768 or 1024-dimensional vector space. Metadata captures image resolution, file format, and associated text captions.
The challenge with images is ambiguity. Unlike text, there's no deterministic ground truth for what constitutes the "correct" retrieval result, making evaluation subjective and dependent on human review.
Audio and Speech Data
Most production systems transcribe audio first using services like AWS Transcribe or Whisper, then embed the transcript.
Direct audio embedding using models like wav2vec produces vectors that preserve prosody and tone but costs 3-5x more in compute and storage compared to transcript-based approaches. Diarization identifies different speakers, which is critical for call center data where you need to distinguish customer statements from agent responses.
Video Content
Video RAG implementations commonly sample frames at 1 FPS as a baseline, though content-dependent strategies perform better. Full-frame indexing at 30 FPS for a 10-minute video means processing 18,000 frames, which becomes impractical at scale.
The implication: higher FPS captures motion-heavy content better but multiplies storage and processing costs. Most systems settle on 1-2 FPS for general content with dynamic adjustment for action sequences.
Structured and Semi-Structured Data
Tables and databases require special handling because they combine structured schema with unstructured content. A product catalog might pair a structured attributes table (price, SKU, category) with images and text descriptions.
Cross-modal alignment happens when you embed both the structured data and associated images, allowing queries like "find products under $50 with a blue color scheme" to search across both dimensions.
Core Architecture of a Multi-Modal RAG System
Multi-modal RAG architecture splits into five modular layers. Each layer has distinct responsibilities, and failures in one layer don't cascade if you've designed proper isolation.
Multi-Modal Data Ingestion Pipelines
Ingestion follows a four-step flow regardless of modality:
- Ingest: Raw files enter the system (PDFs, JPGs, MP3s, MP4s).
- Preprocess: Modality-specific normalization (image resizing, audio sampling rate conversion, video frame extraction).
- Normalize: Convert to formats compatible with embedding models (text tokenization, image format standardization).
- Index: Generate embeddings and store in vector database with metadata.
Steps 2 and 3 are modality-specific, while steps 1 and 4 remain consistent. This separation lets you swap out preprocessing for a single modality without touching the others.
Embedding Models Across Modalities
Embeddings are not interchangeable between modalities. A text embedding model produces vectors in a different space than an image embedding model, even if both output 768 dimensions.
When you upgrade your embedding model, you must re-embed your entire corpus. Re-encoding costs can reach $134 per deployment cycle for representative workloads, and you'll need a migration strategy that handles the gap between old and new embeddings.
Cross-Modal Retrieval and Ranking
When a text query retrieves both text documents and images, the system needs a ranking strategy. Options include confidence weighting (multiply similarity scores by modality-specific confidence factors), heuristic scoring (prioritize certain modalities based on query patterns), or learned ranking models.
Most production systems start with simple confidence weighting because learned rankers add training complexity and require labeled data that doesn't exist yet.
Context Fusion and Representation
Conflicts arise when retrieved text contradicts retrieved images. Your system needs priority rules: trust the most recent source, use confidence scores to weight contributions, or implement majority voting when multiple sources address the same claim.
Without explicit conflict resolution, the LLM receives inconsistent context and hallucinates reconciliation.
Reasoning and Generation Layer
True multi-modal LLMs like GPT-4V and Gemini accept images directly in the prompt. Most systems use a conversion pipeline: image → caption → text → LLM. This loses visual details that captions can't capture.
The limitation is explicit: you're not doing multi-modal reasoning, you're doing text reasoning about descriptions of other modalities.
How Multi-Modal Retrieval Works
Once data from different modalities is ingested and embedded, the next step is retrieving the most relevant context. Each modality requires its own retrieval approach:
Modality-Specific Retrieval Strategies
Each modality uses different retrieval approaches:
- Text: BM25 or dense vector search with semantic similarity.
- Image: CLIP embeddings with cosine similarity between image vectors and text query vectors.
- Audio: Transcript-based vector search or direct audio feature matching using models like wav2vec.
- Video: Frame sampling at 1-2 FPS, embed sampled frames, retrieve based on frame similarity to query.
Cross-Modal Alignment and Similarity
Cross-modal alignment requires embedding models trained on paired data (images with captions, audio with transcripts). Models like CLIP learn joint text-image representations where semantically similar concepts cluster together regardless of modality.
The problem is semantic drift: concepts that align well in training data may misalign in your specific domain, requiring fine-tuning or domain adaptation.
Handling Conflicting or Redundant Context
When multiple retrieved chunks provide the same information or contradictory information, you need deterministic resolution. Priority strategies rank by source authority or recency. Majority voting uses the most common answer across retrieved chunks.
Confidence thresholds filter out low-confidence retrievals entirely. Without these rules, redundant context wastes tokens and conflicts create hallucinations.
Infrastructure Cost, Performance, and Operational Questions
Multi-modal RAG is cost-driven, not model-driven. Your architecture choices dictate whether the system fits your budget.
What are the actual infrastructure costs of running a multi-modal RAG system?
Monthly costs break down by modality:
- Text: Embedding at $0.02 per million tokens, vector storage at $0.10 per GB, retrieval negligible.
- Images: Embedding costs $0.00006-0.0001 per image using commercial models, vector storage at $0.15 per GB plus raw image storage at $0.02 per GB.
- Audio: Transcription at $0.02 per minute, embedding of transcripts follows text costs.
- Video: Frame extraction and embedding follows image costs multiplied by frame count, plus video storage at $0.02 per GB.
- Infrastructure: Compute for embedding generation, vector database hosting ($100-500/month for 100M vectors), and retrieval API costs.
For a corpus of 100,000 documents with 50,000 images, expect $200-400/month in embedding and storage costs before you add compute.
What's the typical response latency for multi-modal queries vs text-only?
Latency components:
- Retrieval: Text-only queries return in 20-50ms, image retrieval adds 50-100ms, video retrieval adds 100-300ms.
- Preprocessing: Image resizing and normalization adds 20-40ms, video frame extraction adds 100-200ms.
- LLM inference: Identical across modalities at 500-2000ms depending on output length.
Text-only RAG typically responds in under 1 second. Multi-modal RAG adds 200-400ms, pushing total latency to 1.2-1.4 seconds for queries that retrieve images or video.
What's the storage requirement for embedding 10,000 images vs 10,000 text documents?
Text documents average 2,000 tokens each with 768-dimensional embeddings stored as float32 (4 bytes per dimension):
- 10,000 documents × 768 dimensions × 4 bytes = 30.7 MB for vectors
- Raw text storage: 10,000 × 10 KB = 100 MB
Images at 1024-dimensional embeddings:
- 10,000 images × 1024 dimensions × 4 bytes = 40.96 MB for vectors
- Raw image storage: 10,000 × 500 KB = 5 GB
Images require 50x more raw storage than text for the same document count.
What's the minimum data volume where multi-modal RAG becomes cost-effective vs text-only?
Cost-effectiveness depends on usage frequency and business value, not model quality. If you query 100 times per month and multi-modal retrieval increases accuracy by 10%, you need to value each accuracy point at more than the incremental cost.
For most systems, multi-modal RAG becomes cost-effective when at least 20% of your queries require non-text context or when missing that context creates measurable business impact (failed customer resolutions, incorrect decisions).
Data Processing and Retrieval Mechanics
Before embeddings can be generated, each modality requires specific preprocessing to ensure the data is consistent, clean, and compatible with retrieval models. Proper workflows reduce noise, improve embedding quality, and make cross-modal retrieval more reliable.
What preprocessing is required for each modality before embedding?
Text workflow:
- Extract text from source (OCR for images, parsing for PDFs)
- Clean formatting (remove headers, footers, page numbers)
- Chunk into 512-1024 token segments with 10-20% overlap
- Tokenize for embedding model
Image workflow:
- Decode from file format (JPEG, PNG)
- Resize to embedding model requirements (224x224 or 384x384)
- Normalize pixel values to [0,1] or [-1,1]
- Convert to RGB if model requires it
Audio workflow:
- Resample to 16kHz (standard for speech models)
- Convert to mono if stereo
- Transcribe or extract audio features
- Chunk if audio exceeds context length
Video workflow:
- Extract frames at target FPS (1-2 FPS)
- Process each frame through image workflow
- Extract audio track and process through audio workflow
- Align frame timestamps with transcript timestamps
Do you transcribe audio first or embed directly for audio retrieval?
Transcribe first for 95% of cases. Direct audio embedding preserves prosody and emotion but costs 3-5x more in compute and storage.
Transcription-based approaches work well when content matters more than tone (documentation, meetings, lectures). Direct audio embedding makes sense for call quality analysis, sentiment detection, and cases where emotion drives the use case.
How do you handle multiple speakers in audio recordings for retrieval?
Diarization splits audio into speaker segments with timestamps. Each speaker segment gets transcribed separately, and embeddings include speaker labels in metadata. When retrieving, you can filter by speaker or search across all speakers.
Without diarization, retrieval returns chunks that mix multiple speakers, making it impossible to determine who said what.
How many frames per second should you process when indexing video content?
A baseline of 1 FPS is typically sufficient for general content. Action-heavy videos benefit from 2 to 3 FPS to capture movement, while static presentations can work at 0.5 FPS. Most production systems start at 1 FPS and adjust dynamically based on scene changes or motion analysis.
Keep in mind that higher FPS increases costs linearly - doubling from 1 to 2 FPS doubles embedding and storage requirements.
Can you query with one modality and retrieve results from a different modality?
Yes, if your embedding models support cross-modal alignment. CLIP embeds both text and images into the same vector space, allowing text queries to retrieve images.
The dependency is on the embedding model - not all models support this. Performance degrades compared to single-modality retrieval because cross-modal similarity is inherently less precise than same-modality similarity.
What's the accuracy of cross-modal retrieval compared to single-modality retrieval?
Cross-modal retrieval accuracy drops 15-30% compared to single-modality retrieval on standard benchmarks. The reason is embedding space mismatch -even aligned spaces lose some semantic precision when translating across modalities.
Text-to-text retrieval might achieve 85% recall@10, while text-to-image retrieval drops to 60-70% recall@10 for the same queries.
Model, Evaluation, and Compliance Questions
Multi-modal RAG systems require careful model selection, rigorous evaluation, and compliance processes. Choosing the right LLM, validating retrieval quality, managing embedding upgrades, and ensuring PII redaction are all critical to reliable, production-ready deployments.
Which LLMs support true multi-modal input vs just text descriptions of images?
GPT-4V, Gemini 1.5, Claude 3, and LLaVA support native multi-modal input -you can pass images directly in the prompt. Most other LLMs (GPT-3.5, Llama 2, Mistral) only accept text.
Systems using text-only LLMs must convert images to captions or descriptions first, which loses visual information. Native multi-modal models cost more per token (2-3x) but provide better accuracy for visual reasoning tasks.
How do you evaluate image retrieval accuracy when there's no clear "correct" answer?
Human review remains the gold standard. Present retrieved images to human evaluators who rate relevance on a 1-5 scale. Proxy metrics include precision@k (what percentage of top-k results are relevant) and normalized discounted cumulative gain (nDCG), which weights top results more heavily.
Qualitative scoring using rubrics (does the image match the query intent, context, and visual elements) provides more nuanced evaluation than binary relevant/not-relevant.
What happens to existing embeddings when you upgrade to a new embedding model?
You must re-embed your entire corpus. The migration strategy involves running both old and new models in parallel during transition, marking records with embedding version metadata, and batch re-embedding in background jobs.
Downtime happens if you cutover before re-embedding completes - queries return degraded results as old embeddings become incompatible with new model spaces.
How do you redact PII from images and videos in compliance with GDPR/HIPAA?
Pre-embedding redaction detects faces, license plates, SSNs, and other PII using detection models, then blurs or blacks out sensitive regions before embedding. This must happen before embedding because embeddings can encode sensitive patterns.
Post-embedding redaction doesn't work -the information is already encoded. Auditing requirements mean logging what was redacted, who accessed what content, and maintaining redaction policies as compliance rules change.
Team, Tooling, and Vendor Considerations
Building and operating a multi-modal RAG system requires specialized skills, careful observability, and informed vendor selection. Teams must balance expertise across machine learning, backend, infrastructure, and evaluation to handle modality-specific challenges and ensure production reliability.
What's the typical team size and skill composition needed to build a multi-modal RAG system?
A realistic team includes:
- 1-2 ML engineers: Embedding model selection, fine-tuning, evaluation.
- 1–2 backend engineers: Ingestion pipelines, vector DB integration, API development.
- 1 infrastructure engineer: Deployment, scaling, monitoring.
- 1 data engineer: Preprocessing pipelines, data quality.
- 0.5 evaluation specialist: Metrics design, human review coordination.
Smaller teams can build basic systems but often struggle with production-scale workloads and modality-specific edge cases.
What observability tools should you use to debug multi-modal retrieval issues?
Log these items per modality:
- Input queries (raw text, image URLs, audio file IDs)
- Embedding generation time and vector output
- Retrieval scores for top-k results
- Modality-specific metadata (image dimensions, audio duration, frame count)
- End-to-end latency broken down by preprocessing, retrieval, and generation
Tools like Prometheus for metrics, Grafana for dashboards, and custom logging for query-result pairs help debug when retrieval fails or returns poor results.
How to Find Development Companies That Can Build Multi-Modal RAG Systems
Focus on vendors who have deployed multi-modal pipelines and managed embeddings, latency, and costs in production.
Required Technical Capabilities and Experience
Non-negotiable capabilities:
- Experience deploying vector databases at scale (10M+ vectors).
- Track record with multiple embedding models and modality-specific preprocessing.
- Production monitoring and incident response for ML systems.
- Cost modeling and infrastructure optimization for multi-modal workloads.
Questions to Ask Before Hiring a Multi-Modal RAG Partner
- What's your approach to handling embedding model upgrades?
- How do you evaluate retrieval accuracy for images vs text?
- What's your strategy for managing cross-modal conflicts?
- Can you provide latency breakdowns for each modality in production systems you've built?
Red Flags When Evaluating RAG Development Vendors
Watch for:
- Overreliance on prompt engineering without infrastructure discussion
- No evaluation strategy beyond LLM self-assessment
- Missing cost models or vague “it scales” claims
- Lack of experience with modality-specific challenges (e.g., audio diarization, video frame sampling)
In-House Teams vs Specialized AI Development Companies
In-house teams control the full stack and can iterate quickly but need to build expertise in embedding models, vector databases, and modality-specific preprocessing.
Specialized companies bring experience and avoid common pitfalls but add coordination overhead and may lack domain-specific knowledge. The trade-off centers on speed to production vs long-term control.
Best Practices for Building Multi-Modal RAG Systems
Effective multi-modal RAG depends on prioritizing high-impact modalities, maintaining modular and observable retrieval, controlling prompt size, and evaluating each modality independently.
Start with High-Value Modalities
Add modalities based on ROI, not capability. If 80% of your queries need text and images but only 10% need audio, defer audio support.
Each modality adds 30-60% to infrastructure costs and requires separate evaluation pipelines. Start with text-only RAG, add the second-highest-value modality, measure impact, then decide if the third is worth it.
Keep Retrieval Modular and Observable
Isolate each modality's retrieval pipeline. When image retrieval breaks, you can debug and fix it without touching text or audio. Log everything: query inputs, retrieval scores, latency per stage, and final results.
Debugging multi-modal systems is harder than single-modality because failures can happen in preprocessing, embedding, or cross-modal alignment.
Control Context Explosion
Every modality you retrieve adds tokens to the LLM prompt. An image might contribute 500 tokens after captioning, audio transcripts add hundreds more, and video frame descriptions multiply quickly. Token costs scale linearly - doubling retrieved context doubles inference cost.
Implement token budgets per modality and drop low-confidence retrievals to stay within budget.
Evaluate Each Modality Independently
Don't measure system accuracy across all modalities at once. Evaluate text retrieval separately from image retrieval.
If overall accuracy drops, you need to know which modality caused it. Per-modality metrics let you prioritize fixes and understand where to invest in better models or preprocessing.
Your Next Move
Multi-modal RAG is infrastructure, not a feature. It's the layer that connects unstructured knowledge across text, images, audio, and video to the reasoning capabilities of LLMs. The architecture decisions you make now determine whether your system scales to production workloads, how much it costs to run, and whether you can maintain it as models improve.
Start with clear cost models, modular components, and rigorous evaluation. Build for the modalities that deliver value, not the ones that sound impressive.
You can also connect with us to review and build multi-modal RAG architecture, evaluate cost and latency considerations, and ensure your system meets production-grade reliability.
Frequently asked questions
When does multi-modal RAG provide real value over text-only RAG?
Multi-modal RAG is valuable when critical information lives in images, diagrams, screenshots, audio, or video - not just text. It becomes cost-effective when at least 20% of queries require non-text context or when missing visual or audio evidence leads to incorrect answers, failed resolutions, or operational risk.
What are the biggest production challenges with multi-modal RAG systems?
The main challenges are cost control, latency, and operational complexity. Image and video embeddings increase storage and compute costs significantly, cross-modal retrieval adds 200–400ms of latency, and embedding model upgrades require re-encoding large corpora. These issues matter far more in production than in prototypes.
How do multi-modal RAG systems handle queries across different modalities?
They rely on cross-modal embedding models (like CLIP) that align text, images, and other modalities into a shared vector space. This allows a text query to retrieve images or video frames. However, cross-modal retrieval is inherently less accurate than same-modality retrieval and requires careful ranking, confidence thresholds, and conflict resolution.
How do you manage cost and latency as more modalities are added?
Production systems prioritize high-ROI modalities, limit frame sampling rates for video (typically 1–2 FPS), enforce per-modality token budgets, and drop low-confidence retrievals. Modular ingestion and retrieval pipelines allow teams to scale or optimize individual modalities without impacting the entire system.
What’s the difference between true multi-modal reasoning and text-based reasoning over captions?
True multi-modal reasoning uses LLMs that accept images or other modalities directly (e.g., GPT-4V, Gemini). Caption-based approaches convert images or video frames into text before reasoning, which is cheaper but loses visual detail and spatial relationships. The choice depends on accuracy requirements, latency budgets, and cost constraints.